
Troubleshooting Professional Magazine
|
XML |
IDL code snippets and other information from the DOM
specification are copied from http://www.w3.org/TR/1998/REC-DOM-Level-1-19981001/,
Copyright © 1998 World Wide Web Consortium , (Massachusetts Institute
of Technology , Institut National de Recherche en Informatique et en Automatique
, Keio
University ). All Rights Reserved. Status of this
document is a w3c recommendation.
|
Rapid Learning: Secret Weapon of the Successful Technologist. Three Rules of Work : 1) Out of clutter, find Simplicity. 2) From discord, find Harmony. 3) In the middle of difficulty lies Opportunity. -- Albert Einstein |
Editors Desk About this Issue's Exercises, PLEASE READ!! What is XML? Some Definitions Anatomy of an XML App Simplified Explanation of the DOM API Learning from the Masters: How Dia Uses XML XML Coding Exercises Wrapup Where to Go From Here Apache Software Foundation and W3C Rule! Thanks and Acknowledgements Linux Log: Open Source Means Quality Education Letters to the Editor How to Submit an Article URLs Mentioned in this Issue
We were all skeptical. After all, the trades had predicted similar futures for push technology, ATM, and a hundred other technologies we've all forgotten. But the trades get it right sometimes. Witness Java and Linux. And definitely XML.
It's 2001. XML is being incorporated in all sorts of projects. The reason you don't hear about it constantly is the *app* that reads, writes, changes and renders the XML is written in a traditional language such as Java, Perl, Python or C++. In that respect XML is data. But used correctly, much of an application's logic can be stored as easily modified XML. The actual C++, Java, Python or Perl code then becomes primarily the user interface. Imagine how nice it would be to implement your business rules as XML. You can!
Then there's the Microsoft connection. Microsoft is gung-ho about XML. Does that make XML an unwise move?
Probably not. Even if Microsoft does what they do best, and somehow manage to proprietarize some dialects of XML, it will be easy to reverse engineer, and may even be legal to do so in spite of UCITA supported anti-reverse engineering license language. Meanwhile, the rest of us can use our own dialects.
"Dialects" are numerous. As will be explained later in this magazine, XML itself is just an extremely intuitive general specification for how to declare something that could be considered hierarchical data, or markup language, depending on your viewpoint. Within that specification, an implementer specifies his own set of rules for naming XML elements, and what other elements each element can contain. That specification can be implemented on paper, or technologically enforced with a DTD or schema. If this paragraph loses you don't worry -- everything in this paragraph will be explained in detail in this magazine.
Unfortunately, XML is poorly documented. There are exceptions. The W3C specifications are easily readable and understandable. But for the most part, XML books do nothing but document XML's syntax, rules and vocabulary, leading the novice reader to ask "so how can I do something with it". If you follow along with the Java examples in this magazine, you'll know exactly what you can do with XML. Once you understand XML at that level, you can port that knowledge to Perl, Python, C++ and other languages that have XML APIs.
XML derives its power from the fact that it can represent anything the human mind can conceive. And that representation is very readable both for a human and for a machine. The concept is so clean that upon understanding it, my first question was "why didn't I invent XML?". I certainly have the intelligence to have invented it -- XML's not rocket science. I've needed it for years, but had to "roll my own" every time I needed a configuration file or data format.
So get familiar with XML. Whether you're in the Microsoft world or the Open Source world, or somewhere in between, you'll need to interface with it in the next couple years.
How can a Troubleshooter benefit from XML? XML should make applications simpler to diagnose and simpler to tweak. And an XML file provides loads of testpoints from which you can manipulate the apps interacting with it. It brings back some of the Troubleshooting advantages of the intermediate files of the Cobol era, but unlike those, it's persistent and useful in and of itself.
So whether you're a Troubleshooter, programmer, DBA, Sysadmin, or just a person who likes technological progress, kick back, relax, and enjoy your magazine.
The coding exercises are all in Java. My research indicates Java has the most mature support for XML. Once you download Xerces from the Apache Foundation and install it, these exercises work on a Linux box with Java installed. Java is the most straightforward way I could offer coding exercises.
I had originally intended to do the exercises in both Perl and Java, but Perl DOM support proved problematic, and there wasn't enough time.
Xerces-Perl for Linux has shipped!
After I had done most of the exercises in Java, I got an email message that there now exists. It's so new it's not on CPAN, and I couldn't find it on xml.apache.org. It's been tested only on Debian. But Xerces is a killer tool, and a Perl/Linux version is a good thing. Stay tuned. More info as it comes in.
Rest assured, though, if you're a Perl, Python or C++ person, everything you learn in this tutorial will apply to XML in your language of choice. In every exercise, I used only calls defined in the DOM and SAX specifications. I used no "native Javaisms" to manipulate XML.
Java is a killer language. It's portable, ubiquitous, free beer and in some implementations free speech, it's fast enough, and it's corporationally correct. These are some more reasons I chose Java for the XML coding.
This tutorial was written, tech edited, and tested in Linux (Mandrake 7.2). No effort was made to test under Windows. Instead I used the time to delve deeper into XML. That being said, I know of no reason the Java exercises shouldn't work on a Windows box that's properly configured with Java and Xerces. If you don't have a Linux box, and you can't get your hands on one, by all means use a Windows box for the Java exercises. You'll need to convert some of the shellscripts to batch files, and you'll need to do a Windows install of the JDK and Xerces instead of a Linux install, but that should be pretty easy.
The Dia diagramming program, basis of the "Learning from the Masters: How Dia Uses XML", originated on Linux but has been ported to Windows. The Linux package is more mature, so if you have a choice you might want to do that exercise on a Linux box. And that's an exceptionally important exercise, so even if you don't have a Linux box, please try to find someone who will let you use theirs for this exercise. If you don't know anyone with a Linux box, find your local Linux User Group (LUG) and beg someone there to let you use their box to do the Dia exercises.
Personally, I felt more comfortable working on a Linux platform. If you feel more comfortable on a Windows platform, I'd imagine you should be able to get this tutorial to work from within Windows, although of course I haven't tested it on Windows.
|
This is a far trickier question than you can imagine, and I think once you master the answer, everything else falls into place.
One possible answer is that XML is a markup language. And that's absolutely true, as anyone who sees the bracketed begin and end tags for its elements can attest. This answer is true, but almost useless. Because to think of XML as HTML on steroids is to relinquish 90% of XML's functionality.
Another possible answer is that XML is a styles-based markup language, rather than an appearance-based markup language like HTML. Once again, so true, and so useless.
I think a much better definition for XML is a specification for a markup language that can be used to represent almost any concept. Keeping in mind that neither phonebook, person, info nor name are keywords, imagine how the following could be used:
<phonebook> <person lname="Smith" fname="John"> <info name="workphone">800-555-1212</info> <info name="homephone">407-555-5555</info> <info name="relationship">Skating buddy</info> <info name="skatetype">Racing inlines</info> <bicycle serialno="432845" speeds="21" tires="700cc"></bicycle> </person> <person lname="Jones" fname="Mary"> <info name="workphone">800-555-1234</info> <info name="homephone">407-555-2222</info> <info name="relationship">Coworker</info> <info name="yearsatcompany">8</info> </person> </phonebook>You've just implemented a phone book. Add a user interface and you're done. The user interface reads the fields from the XML, and places the values from those fields in on-screen text boxes, queries the user to change the contents of those fields And notice that if you write that user interface well, you can add new fields simply by changing the XML. You can have a program on the other end that puts the finished XML into a database, assuming the database is flexible enough to represent such data.
Notice a few facts about the preceding XML code:
<person> <lname>Smith</lname> <fname>John</fname> <info name="workphone">800-555-1212</info> <info name="homephone">407-555-5555</info> <info name="relationship">Skating buddy</info> <info name="skatetype">Racing inlines</info> </person>Please remember there are no reserved words in the preceding example. info and name are just strings I decided upon to make it self documenting. As an alternative to the preceding, I could have even used info tags to accomplish the same purpose:
<person> <info name="lname">Smith</info> <info name="fname">John</info> <info name="workphone">800-555-1212</info> <info name="homephone">407-555-5555</info> <info name="relationship">Skating buddy</info> <info name="skatetype">Racing inlines</info> </person>Your choice of attributes vs. elements depends on things such as whether you'll need more than one of the entity (no two attributes of a single element can have the same name), and whether you should always have the entity (that might favor using an attribute). Also, use elements if order is important, because the XML specification doesn't specify the order of attributes, so parsers don't necessarily preserve attribute order. All this will be explained later in this magazine.
The preceding examples have used XML as a hierarchical representation.
But it can also be used as stylized markup:
<heading level="3"> Why XML is So Great</heading> <paragraph>XML is <emphasis>absolutely wonderful!</emphasis>And it's not just because <emphasis>XML is <newword>Corporationally Correct</newword>!</emphasis></paragraph> <paragraph>Now let's talk about... |
In the preceding, the XML markup describes the styles, or functionality, of marked up text. It's up to the application rendering the XML to assign an appearance to such styles. Even the relationship between style and appearance can be moved out of the application using XSL (Extensible Style Language). XSL is a separate but related subject that is not discussed in this issue of Troubleshooting Professional.
Tags must be nested, never interlaced. The following is not allowed:
XML <emph>is <italic>great</emph> and good.</italic> |
The well formed way to write the preceding would be to nest tags, like
this:
XML <emph>is <italic>great</italic></emph><italic> and good.</italic> |
Because tags can't be interlaced, but instead must be nested, all XML represents a hierarchy. For instance, the preceding snippet could be thought of like this:
XML is <emphasis> truly <italic> great <italic> and fantastic.Generally speaking, in XML intended to represent a hierarchy, an element containing a text node contains no other elements or text nodes, but in XML intended to represent markup, an element often contains several text nodes and several other elements. But this is not a rule, only a custom.
I believe the best way to learn XML is through the DOM (Document
Object
Model)
spec, so DOM is discussed voluminously in later portions of this issue
of Troubleshooting Professional Magazine.
|
|
| Document | The data contained in an entire XML file:
<?xml version="1.0"?> <shellinterface> <getch mthd="cmd" access="backtick">getchbsd.pl</getch> <pathseparator>;</pathseparator> </shellinterface> |
| Element | The entity defined by a start tag and end tag, but not the entities
contained between the start and end tags:
<getch mthd="cmd" access="backtick">getchbsd.pl</getch>Note that all elements are nodes, but not all nodes are elements. Elements inherit all methods of nodes, and add some of their own. Nodes are discussed later in this table. |
| Attribute | The name/value pairs enumerated in an element's start tag:
<getch mthd="cmd" access="backtick">getchbsd.pl</getch> |
| Text Node | The text between the open and close tag of its parent element:
<getch mthd="cmd" access="backtick">getchbsd.pl</getch> |
| Node | The most atomic XML entity that is programmatically useful. Elements,
attributes and text nodes are all nodes. There are other node types which
are described in the DOM spec:
// NodeType const unsigned short ELEMENT_NODE = 1; const unsigned short ATTRIBUTE_NODE = 2; const unsigned short TEXT_NODE = 3; const unsigned short CDATA_SECTION_NODE = 4; const unsigned short ENTITY_REFERENCE_NODE = 5; const unsigned short ENTITY_NODE = 6; const unsigned short PROCESSING_INSTRUCTION_NODE = 7; const unsigned short COMMENT_NODE = 8; const unsigned short DOCUMENT_NODE = 9; const unsigned short DOCUMENT_TYPE_NODE = 10; const unsigned short DOCUMENT_FRAGMENT_NODE = 11; const unsigned short NOTATION_NODE = 12;The Node interface of the DOM spec contains most of the navigational methods. Note that all elements are nodes, but not all nodes are elements. Elements inherit all methods of nodes, and add some of their own. |
| Document element | Top level element, of which there can be only one per XML file:
<shellinterface> <getch mthd="cmd" access="backtick">getchbsd.pl</getch> <pathseparator>;</pathseparator> </shellinterface> |
| DTD | A sort of type declaration for XML. Here's an ultra-simple one:
<!DOCTYPE docelement [ <!ELEMENT docelement (#PCDATA)> ]>Note that docelement is NOT a reserved word. |
| Well formed | An XML file conforming to the XML syntax rules, including:
|
| Valid | Well formed, AND conforming to the rules of the DTD. |
| Schema | Performs a function similar to a DTD. |
| DOM | Stands for Document Object Model. A method of placing an entire XML file's hierarchy, with all its elements, in a memory object. This memory object is built for quick lookup, traversal and modification. |
| SAX | Stands for Simple API for XML. An event driven method of dealing with an XML file. Instead of containing the entire hierarchy in memory at one time, it presents elements as events which can then be exploited by your code. SAX has the advantage of less memory consumption for large files, but has the disadvantage that the programmer must write code to save anything he wants saved, and must write changes to the XML file in sequential order. DOM allows random changes to elements. Because needn't keep entire files in memory at once, SAX is universally useful, whereas DOM is not useful for truly huge XML files. |
| DOM Document | In the DOM standard, an object containing the entire hierarchy, elements, and information of an XML file. |
| DOM object | Any object contained within a DOM document. Vague, ambiguous, and misunderstood -- don't use this term. THIS TERM IS NOT A SYNONYM FOR DOM document!!! |
| Namespace | A method of uniquifying tag names from various XML varients:
<shape xmlns="http://www.daa.com.au/~james/dia-shape-ns" xmlns:svg= "http://www.w3.org/TR/2000/03/WD-SVG-20000303/DTD/svg-20000303-stylable.dtd"> <name>Circuit - Vertical Zener Diode</name> <svg:svg width="3.0" height="3.0"> <svg:line x1="0" y1="0" x2="0" y2="2" /> <svg:polygon points="-0.8,2 0.8,2 1,2.6 0.8,2.1 -0.8,2.1 -1,1.5" style="fill: inverse" /> <svg:polygon points="0,2.1 -1,3.85 1,3.85" style="fill: default" /> <svg:line x1="0" y1="3.85" x2="0" y2="5.85" /> </svg:svg> |
|
|
An XML application reads an XML file, after which it can modify and rewrite the XML, and/or it can print output based on that XML (commonly called "rendering"). Note that "rendering" can take widely diverse forms, including changing which fields are available on a form, printing a vector graphic, or the most obvious case of rendering marked up text. Rendering can even take the form of configuring an application, or executing remote procedures.
The DOM model is easiest to understand, so here is the architecture
of an XML app using DOM:
So here's what happens: A parser reads the XML file and builds a DOM document to match the XML file. From that point until a save is performed, all interaction between the app and XML hits the DOM document rather than the corresponding XML file. It's interesting to note that almost all XML parsers use SAX. The reason is simple enough. Before you build a DOM document you must detect events such as start of element (start tag encountered), end of element (end tag encountered), new attribute (name followed by equal sign followed by quoted string encountered), and the like. So DOM can be thought of as an extra abstraction to lessen the programmer's workload, at the expense of memory usage.
Modifications are made directly to the DOM document. Elements can be added, deleted, renamed, rearranged. Text nodes can be added, deleted or changed. Elements can be moved either within the same level, or promoted or demoted to different levels.
Obviously, the DOM is modified in apps that rewrite the XML file. But DOM modification is also often done in an app that only renders the XML. The classic example is in a "DOMWalker" app, which simply walks the DOM tree and prints what it finds in a hierarchical outline. In fact, the newlines and spaces intended to make the XML file more readable are actually legitimate text nodes in XML, but in an XML app concerned only with a hierarchy they're extraneous. Therefore, the first thing a DOMWalker program does is delete text nodes made up only of whitespace. Source code for an example DOMWalker is given later in this magazine.
Rendering is the heavy part of most XML apps. It's often graphics intensive. Consider the Dia vector drawing program, which keeps all drawing information in XML but renders as geometric shapes. Often there are several rendering processes, one for each kind of output. Thus a book authored in XML could be rendered as a paper book, as a PDF, as a Postscript file, or as an HTML page or series of HTML pages. Indeed, this is one of the primary benefits of styles based documents. Often the rendering itself is decoupled from the app by use of XSL (eXtensible Style Language), much the same as program logic is decoupled from the app using XML.
Rewriting the XML file is actually easy -- about what you'd expect for your last class project in a college Programming 101 course. In the case of DOM, you've already assembled the output in a DOM document, so you just walk its tree and write the markup.
In the case of SAX based XML apps it's a little harder because you often
don't read the information in the same order you want to write it. In other
words, if your app's specification calls for something occuring later in
the input modifying something earlier in the output, you can't just use
a read-write loop. So you do the typical stuff -- keep some things in memory,
or maybe write an intermediate file and then sort it, or run 2 passes through
the XML. This is why for apps interacting with guaranteed small XML files,
DOM is better.
|
|
If you understand DOM, you're 90% of the way to understanding XML.
What you might think of as a "DOM object" is really an instance of the
Document class:
DOMParser dp = new DOMParser();
dp.parse("myfile.xml");
Document doc = dp.getDocument();
|
In the preceding code, the parser delivers an instance of Document, called doc, which contains the entire information hierarchy contained in the original file myfile.xml. You can use methods from the DOM API to extact any info from the DOM document if that information was in the original XML file (with a very few exceptions)
The simplest explanation of a DOM document is that it's an in-memory tree containing all info from the XML file hierarchy, together with with varous methods to navigate that tree, to get information from a specific node, and to add, delete, rearrange or modify nodes. If you can navigate, get, and change, that's pretty much all you need to do with a hierarchy.
There's no better documentation on DOM than W3C's DOM specification papers, available at their website. To learn XML, you should spend about a day reading the parts dealing with XML (not with HTML). It is time *very* well spent.
The purpose of this article is to help you understand what you will see when you read the DOM spec, so that you don't go off on the wrong track and you aren't overwhelmed.
Throughout this article, keep in mind that DOM methods enable three main activities:
Most of the methods to read and modify elements operate on the element with the checker. HOWEVER...
Note: The "checker" metaphor will be used extensively throughout this issue of Troubleshooting Professional.
My assertion that they operate by moving a checker around is not quite
accurate, because these navigation methods do not change the state of the
DOM document. Instead, they simply deliver a node. The programmer records
the current position by assigning the returns of these methods to a node
object. That node object marks the place of the "checker".
|
Although attributes are nodes, they are invisible to the navigation methods and public variables listed below. There are specialized methods and public variables to access and navigate attributes. |
The following is a list of the major navigational methods, and the equivalent
public variables, and the interfaces in which these methods and public
variables are implemented. Immediately below the list is a sample hierarchy
to walk. Observe the naming convention that in general the variable name
is converted to the method name by capitalizing the first leter, and prepending
either get or set as appropriate. For the time being,
don't worry about the Interface column:
| Method | Equivalent public variable | Interface |
| getOwnerDocument()
getDocumentElement() getFirstChild() getLastChild() getNextSibling() getPreviousSibling() getParentNode() |
readonly attribute Document ownerDocument;
readonly attribute Element DocumentElement; readonly attribute Node firstChild; readonly attribute Node lastChild; readonly attribute Node nextSibling; readonly attribute Node previousSibling; readonly attribute Node parentNode; |
Node
Document Node Node Node Node Node |
 |
||
In plain English, you start with the checker on the document element. At every juncture:
That brings up an important point. You shouldn't be able to go down from an element if you've already done so. When you first arrive at an element via a downward or a rightward movement, you descend if you can. But sooner or later, you'll come back up to that same element after you've gone as far right as you can in the level below the element. Obviously, you don't want to descend again, as that would make an infinite loop as described in the following indented paragraph:
From A move right to B. From B move down to 1. From 1 move right to 2. From 2 move right to 3. From 3 move up to B. From B move down to 1...So you implement a boolean control variable (let's call it ascending) that is true when you ascend to a node, and false otherwise. The definition of "can go down" then becomes not only that there are children, but also that you are not ascending. The following Java loop walks a tree and calls once printNodeInfo() for each element:
mynode=doc.getDocumentElement();
while (true) {
if (!ascending) {
printNodeInfo(mynode);
}
if ((mynode.hasChildNodes()) && (!ascending)) {
mynode=mynode.getFirstChild();
ascending = false;
}
else if (mynode.getNextSibling() != null) {
mynode=mynode.getNextSibling();
ascending = false;
}
else if (mynode.getParentNode() != null) {
mynode=mynode.getParentNode();
ascending = true;
}
else {
break;
}
}
|
In the preceding Java code, object mynode is the "checker". Basically, what the code says is perform an action (printNodeInfo() in this case) on the checkered element, and then make your move. Move the checker down if you can, otherwise move it right if you can, otherwise move it up if you can, otherwise you're done (because you've returned to the document element).
Oh, and one more thing. The preceding navigation accesses not only elements, but also text nodes. You can discern the two types with the nodeType public variable or the getNodeType() method implemented in the Node interface. However, remember that the preceding navigation methods do NOT bring the checker to rest on attributes. Attributes have their own navigation and access methods. Using the "checker" metaphor, they could be said to have their own checker.
<person> <lname>Smith</lname> <fname>John</fname> <info name="workphone">800-555-1212</info> <info name="homephone">407-555-5555</info> <info name="relationship">Skating buddy</info> <info name="skatetype">Racing inlines</info> </person>It's likely you'll have info elements, and you might want to list them. That's when you use the getElementsByTagName(name)syntax, which delivers a NodeList (similar to an array) of all such subelements. You can then loop through the NodeList to put your checker on each of those similarly named elements. This can be done even when you know there will be only one such named element.
readonly attribute DOMString nodeName; attribute DOMString nodeValue; readonly attribute unsigned short nodeType;In other implementations, including Java, you use methods to accomplish these same things:
public String getNodeName(); public String getNodeValue(); public short getNodeType();Some implementations allow you to do either.
myElement.parentNode.replaceChild(newElement,myElement)Otherwise, try something like this:
Element tempElement = myElement; myElement = (Element)myElement.getParentNode(); myElement.replaceChild(newElement,tempElement);An element can be inserted before the checker like this:
Element tempElement = myElement; myElement = (Element)myElement.getParentNode(); myElement.insertBefore(newElement,tempElement); myElement = tempElement; //Return to original positionAn element can be appended after the checker like this:
Element tempElement = myElement; myElement = myElement.getParentNode(); myElement.appendChild(newElement,tempElement); myElement = tempElement; //Return to original positionOnce the new node is in place, you can change its value with its nodeValue public variable, or the setNodeValue() method.
The "checker" element can be deleted like this:
Element tempElement = myElement; myElement = myElement.getParentNode(); myElement.removeChild(newElement,tempElement);In the case of deletion, you can't move the checker back to the original node because the original node is gone. The programmer handles this by storing where he wants to go after the deletion. For instance, a DOM walker that deletes all blank text nodes keeps a copy of where the checker was in the previous iteration, and upon deletion goes back there. In the next iteration, it gets the node "after" the deleted one.
Navigating attributes is simpler than navigating elements because attributes cannot contain anything else, and because you cannot have two attributes with the same name.
To get the value of a named attribute, use the my element.getAttribute(attribname) syntax. To get an attribute object, use the element.getAttributeNode(attribname) syntax. An attribute object contains the attribute name, its value, whether the value was specified as opposed to default, and the element that owns the attribute.
An element's attributes are accessed as an array, not with a getNext
type of API. Different implementations are different, and you'll need to
experiment, but typically you get the array, get the array's length, and
then loop through the attribute nodes. You get the array with the attributes
public variable or the getAttributes() method, defined in the
Node
interface, and the number of elements with the length public variable
defined in the NamedNodeMap interface, then loop, accessing each
attribute with the item() method implemented in the NamedNodeMap
interface, then accessing the attribute's
name and value
public variables from the Attr interface. If your implementation
uses only methods, use getNodeName() and getNodeValue().
The following is some Java code to do that:
NamedNodeMap attribs = thisNode.getAttributes();
for(int i=0; i < attribs.getLength(); i++){
Node attrib = attribs.item(i);
System.out.print(attrib.getNodeName());
System.out.print("=\"");
System.out.print(attrib.getNodeValue());
System.out.print("\"\n");
}
|
Once again, in many DOM implementations the preceding doesn't work.
In some cases attribs is an array in the computer language's native
format, after which it can be traversed using constructs of the language.
Experiment.
|
|
This article may seem very tedious. You might be tempted to skip it. But unless you already have a deep understanding of XML and a feel for what makes good XML, this is the most important article in this magazine. If you skip this article, you'll likely fail (or at least not understand what you're doing) when you try coding the XML app exercises later in this issue. But if you spend the hour it takes to do this article's exercises, and the extra 1 to 3 hours to debrief yourself so you really understand what has happened, you will have a deep, intuitive grasp of XML, and nothing will stop you.
!! CAREFULLY READ AND PARTICIPATE IN THIS ARTICLE !!
Many Linux distros come with a vector graphics drawing program called Dia. Dia is an Open Source alternative to Visio. It stores not only drawings but also template shapes in XML, so it's very extensible and could surpass Visio. Using only a text editor, you can create brand new template shapes, each with an arbitrary number and placement of connnection points. It's incredible.
Dia is available on many Linux distros. I know it's on Mandrake 7.1 and 7.2, although it's not on the menu. But it's in /usr/bin. If Dia isn't installed, see if you can install it from your distribution CD (check for a file with a name like dia-0.86-2mdk.i586.rpm in your RPMS directory on Red-Hat derived distros).
If your distro didn't come with Dia, here are some places you can get
it:
| Type of install | Where to find it |
| Source | http://www.lysator.liu.se/~alla/dia/dia.html |
| Debian Package | http://packages.debian.org/unstable/graphics/dia.html |
| RPM files | http://www.rpmfind.net, then search for dia. |
Dia is a diagramming tool most suitable for data flow diagrams, network system diagrams, or basically anything resembling a block diagram. Connection lines stay connected as you move components around. You can add bends to connection points by right-clicking a multi-segment connection line and choosing "add new segment". Outstanding!
All drawings are stored as gzipped XML files. You can modify a drawing two ways -- graphically, or by editing the XML. Although the latter is much more time consuming and harder to visualize, for work requiring exact measurements it might be preferable.

That's the Dia toolbox. From the menu, click file, then new, and you'll be brought to a blank page. Right click the blank page, choose file, then save as, and save it as blank.xml.gz. Now close the drawing by right clicking the empty drawing and choosing close.
Remember, Dia saves its drawings as gzipped xml files. View blank.xml.gz with the following command:
zless blank.xml.gzYou'll see an XML file whose document element is <diagram> (with a namespace appended -- well discuss this much later). Second level element are <diagramdata> and <layer>. Examine the <layer> element's XML code:
<layer name="Background" visible="true"/>There's no end tag. In XML, when an element contains no subelements or text nodes, the start tag and end tag would butt up next to each other. To enhance readability in such cases, XML syntax allows a forward slash before the ending angle bracket of the start tag to denote an end tag. The layer element has two attributes, name, with value "Background", and visible, with value "true". Remember that none of these strings are XML reserved words.
In the case of the <diagramdata> element, it has tons of subelements, most of which are <attribute> elements (this is not an XML reserved word). As you can see, there's an <attribute> element for the drawing's background, an <attribute> element for the "paper" used with the drawing (size, margins, portrait/landscape and the like), an <attribute> element for the grid to be used, and an <attribute> for something called "guides", of which there's apparently a horizontal and a vertical instance. People hear me well, a lot of the Dia application is specified by this layout, and this layout is extremely readable. Behold the power of XML!
You'll notice a couple other things. <attribute> elements contain other <attribute> elements (or don't, as the individual elements data dictates). XML allows storage of very freeform data. You'll also notice a <composite> element. This is intended as a container for multiple elements.
$ gunzip ellipse.xml.gz blank.xml.gz $ diff ellipse.xml blank.xml | lessYou get something like the following:
58,76c58 < <layer name="Background" visible="true"> < <object type="Standard - Ellipse" version="0" id="O0"> < <attribute name="obj_pos"> < <point val="1.3,3.6"/> < </attribute> < <attribute name="obj_bb"> < <rectangle val="1.25,3.55;6.9,5.95"/> < </attribute> < <attribute name="elem_corner"> < <point val="1.3,3.6"/> < </attribute> < <attribute name="elem_width"> < <real val="5.55"/> < </attribute> < <attribute name="elem_height"> < <real val="2.3"/> < </attribute> < </object> < </layer> --- > <layer name="Background" visible="true"/> |
Look it over for a second. All that happened was a single <object> element, whose type attribute has value "Standard - Ellipse", has been inserted into the <layer> object whose name attribute has value "Background". The <object> element contains several <attribute> elements describing all the "attributes" you'd expect of an ellipse, such as position (X and Y coords), the top left corner (X and Y coords), the width and the length. There's also an <attribute> element called obj_bb which is the four points comprising the bounding box of the object. It's all very readable.
Notice there's no color listed? Let's give the ellipse a fill color and observe the change.
gzip ellipse.xmlNow open ellipse.xml.gz in Dia. Drag a rectangle around the ellipse to select it without the risk of moving it. Now right click the ellipse, choose dialogs, then properties. Click the color bar next to "Fill colour", and crank the blue all the way down until it's a pure yellow. Now click the color bar next to "Line Colour", and crank up the blue until the line is pure blue. Right click the drawing, choose File/save as, and save the drawing as colors.xml.gz. Finally, click the drawing, choose file/close to close the drawing.
Now use the following commands to view the difference between blank.xml.gz and ellipse.xml.gz:
$ gunzip colors.xml.gz ellipse.xml.gz $ diff colors.xml ellipse.xml | lessYou get the following:
75,83d74 < <attribute name="border_width"> < <real val="0.1"/> < </attribute> < <attribute name="border_color"> < <color val="#0000ff"/> < </attribute> < <attribute name="inner_color"> < <color val="#ffff00"/> < </attribute> |
It's simple to see what happened. An <attribute> element with attribute name having value "inner_color" was created with a subelement called <color>, with a val attribute whose value is"#ffff00" (pure yellow), to describe the fill color. An <attribute> element called "border_color" was created with a subelement <color> with attribute val valued at "#0000ff" (pure blue), to describe the line color. And an <attribute> element called "border_width" with a subelement called <real>, whose val attribute has value at "0.1". Note that when I say the <attribute> elements were called such and so, what I really meant was that they had an XML attribute called name, and the value of that attribute was such and so.
If you're like me, you wonder why a border width entity was created. I'd guess that there was no border until you specified its color.
: NOTE : Look what the application has done. Every property of the ellipse is described with an <attribute> element. They could have had special elements called <border_width> and the like, but they didn't. Likewise, they have a subelement to describe the value of the property. Each such subelement has a name corresponding to what is being measured, and a value corresponding to the actual value of the property. Why did they do this? they could have just as easily done something like this:
<border_color units="color" value="#0000ff"/>But that wouldn't have been as generic. What the authors of Dia have done is to create a system where any property can be described, and all properties can be read into the app. This is how the pros do XML.
Anyway, you now see how it handles colors. We've done quite a bit
of work manipulating Dia and noting the result in XML. Now let's go the
other way.
<attribute name="elem_width"> <real val="5.55"/> </attribute> <attribute name="elem_height"> <real val="2.3"/> </attribute>As you remember, you made the ellipse much wider than it was high. That's why the elem_width is much bigger than elem_height. Using the cut and paste of your text editor, carefully exchange the values associated with elem_width and elem_height, and then resave the file. If things go as expected, pulling the diagram up in Dia should now show an ellipse higher than wide.
Naturally, you need to gzip the file again:
gzip colors.xmlAnd finally pull the drawing up in Dia. And sure enough, the ellipse is now higher than wide (if not, troubleshoot).
resp='y' echo $resp while test "$resp" = "y"; do dia test.xml.gz rm test.xml gunzip test.xml.gz vi test.xml gzip test.xml echo -n "Do it again? (y/n)===>" read resp done |
Save the preceding script as rdia and chmod rdia as executable by all (chmod a+x rdia).
: NOTE :
This script won't function if there doesn't exist a test.xml.gz, so before using the script go into Dia, create a blank drawing, and save it as test.xml.gz. Finally, run the script and experiment editing both the XML text and the Dia graphics, and note how changes in one environment appropriately change the other.
If you don't like the VI editor, substitute the name of your favorite Linux editor for vi in the script
|
This script will not procede to editing the XML file until you completely exit the Dia application. You exit Dia after saving your work by clicking the close icon on the Dia toolbox. |
If you "gum up" the XML so badly that you can't pull up the file in Dia, simply create a new blank test.xml.gz in Dia.
Once in the XML file, you'll notice that the blue box object appears before the yellow ellipse object. That's intuitive, because objects appearing later get thrown on the canvas "on top of" existing objects. To test this theory, cut the XML for the yellow ellipse object, and place it below the XML for the blue box object. Save the file and continue. If everything's gone right you should now see the blue box on top of the yellow ellipse.
See the beauty of XML. A concept like "how do I signify which objects are on top of which others would normally be difficult to implement. But if the app stores its info in XML, it's a no-brainer.
Notice that all objects are inside a single layer object. If you want to have a little fun, within the Dia environment send different objects to different layers, then view the results in XML. Note that I've had cases where seemingly correct changes to layers caused Dia not to load the file, and I've even seen where simply saving the file in VI caused Dia not to load the file. The good news is I've always been able to correct this type of problem by deleting the new layer in VI, after which Dia would load the file. When all is working well, you can manipulate layers in the XML file and have the results show up exactly as expected in Dia.
Experiment. The possibilities are endless.
<?xml version="1.0"?> <diagram xmlns:dia="http://www.lysator.liu.se/~alla/dia/"> |
The first line is the XML Declaration, and basically gives the XML version. The second line declares a namespace, called dia, and equates it with the URI http://www.lysator.liu.se/~alla/dia/. Note that I said URI, not URL. There's a subtle difference. But anyway, don't expect to find anything at that URI. It would be coincidence if you did.
The second line is a namespace declaration. It declares a namespace called dia, associating it with the unique identifier "http://www.lysator.liu.se/~alla/dia/". The reason URI's are used is because they are the best hope for a unique identifier worldwide. For instance, if I were to author a new XML file and wanted to give it a new namespace, I could name it after a directory on Troubleshooters.Com, knowing that Troubleshooters.Com is mine to control. Of course, this doesn't stop someone else from using Troubleshooters.Com as part of their unique identifier, but that would be very bad ettiquette.
A namespace is simply an "area" or "scope" (for want of better words) within which each name is guaranteed unique. This is important as Internet enabled apps use more and more XML files from more and more sources. The basic idea is that all elements could be prepended with dia:, in which case, for instance, <dia:attribute> would be differentiated from, let's say, <umenu:attribute>.
For the time being this is isn't important in the learning process, but remember it in case you later see this syntax. And remember, you WILL NOT find a DTD or schema for the XML file at the URI. The URI is just a method of unique identification.
Now draw yourself an ellipse (wider than high) and a rectangle (wider than high). Now drag a band around both to select them, right click on either object, select objects then group, and note that instead of both objects being selected, the pair of objects is selected. You cannot select one object without selecting both, and when you move one both move. Save the drawing and quit Dia.
Viewing it XML, you see that the two objects are now between a <group></group> pair of tags. The complex task of grouping objects is handled just that simply.
Go back to Dia, select the group, right click either object in the group, and choose objects and ungroup. The objects become two separate objects now. Save the drawing and exit Dia. Looking at the XML, you'll notice everything's the same except the <group></group> pair of tags is gone.
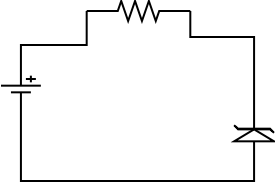
First erase everything from the drawing with the Ctrl+X keystroke combination.
Next, draw the battery, resistor and zener diode using their buttons from
the Circuit template group, which will probably be the default. The buttons
for battery, resistor, and zener are, respectively: ![]() ,
, ![]() ,
and
,
and ![]() . Each of these graphic
circuit components have connection points at their leads, so use the Zig
Zag Line button (
. Each of these graphic
circuit components have connection points at their leads, so use the Zig
Zag Line button (![]() )
to create zig zag lines, clicking on one connection point and dragging
to the one on the next electronic component. Try to arrange the components
so they look something like the drawing above. When you have something
resembling the preceding drawing, save it and exit Dia to see the XML you've
created.
)
to create zig zag lines, clicking on one connection point and dragging
to the one on the next electronic component. Try to arrange the components
so they look something like the drawing above. When you have something
resembling the preceding drawing, save it and exit Dia to see the XML you've
created.
: NOTE:
If you're really having trouble drawing this drawing in Dia, click here.
First, notice that you've created the following objects:
<object type="Circuit - Vertical Powersource (European)" version="0" id="O0"> <object type="Circuit - Horizontal Resistor" version="0" id="O1"> <object type="Circuit - Vertical Zener Diode" version="0" id="O2"> <object type="Standard - ZigZagLine" version="0" id="O3"> <object type="Standard - ZigZagLine" version="0" id="O4"> <object type="Standard - ZigZagLine" version="0" id="O5">Observe that each object has an id attribute with values from "O0" through "O5". That fact will come in handy investigating the mechanics of line to circuit component connections. Note that depending on the order in which you placed components and lines, your ID numbers may vary.
Next, notice that each Zig Zag line has a <connections> element, containing two <connection> elements. The following code shows the <connections> elements for the first, second, and third zigzag lines respectively:
<connections> <connection handle="0" to="O0" connection="0"/> <connection handle="1" to="O1" connection="0"/> </connections> <connections> <connection handle="0" to="O1" connection="1"/> <connection handle="1" to="O2" connection="0"/> </connections> <connections> <connection handle="0" to="O2" connection="1"/> <connection handle="1" to="O0" connection="1"/> </connections>So let's describe each zigzag line's connections in English. Line 1 connects to handle 0 of object O0 (the battery), and also to handle 1 of object O1 (the resistor). It connects the battery to the resistor. Zigzag 2 connects to handle 0 of object O1 (the resistor, and please remember that handle 1 of the resistor is already taken), and also to handle 1 of object O2, the zener. It connects the resistor to the zener. Zigzag 3 connects to handle 0 of object O2 (the zener), and handle 1 of object O0 (the battery). It connects the zener to the battery, completing the circuit.
You can actually modify the XML to put the program in an illegal state. On the following line:
<connection handle="0" to="O2" connection="1"/>Change the 0 to 1 in the handle="0" attribute, save, and pull it up in Dia, and note that everything looks fine. Now click on the zener diode, and note that Dia aborts. Change the 1 back to 0 and confirm that the illegal state has been taken care of.
Basically, what happened is that a line with nonzero length had its begin and end handles at the same point -- an error condition in both Dia and mathematics.
That brings up an interesting hypothesis. Perhaps we should strive to make XML apps so mutable that you can't put them in an illegal state by editing the XML. Such an app would indeed have all its logic in the XML file, and the executable app would merely be a viewer. Perhaps that hypothesis is a little over the top, but it's an interesting thought.
$ locate Circuit.sheetIf that doesn't produce results, do a brute force search through the /usr tree:
# find /usr -type f | grep "Circuit\.sheet" /usr/share/dia/sheets/Circuit.sheet /usr/src/RPM/SOURCES/dia-0.86/sheets/Circuit.sheet #In the preceding example, the Dia shared directory would be /usr/share/dia.
/* XPM */
static char * smily_xpm[] = {
"22 22 3 1",
" c None",
". c #000000",
"+ c #FFFFFF",
" ",
" ",
" ",
" ",
" ",
" ",
" .............. ",
" . . ",
" . . . . ",
" . . ",
" . . . ",
" . . . . ",
" . .. .. . ",
" . ... . ",
" .............. ",
" ",
" ",
" ",
" ",
" ",
" ",
" "};
|
As you can see, it's really just a dot picture of the icon to be displayed, plus the size and a few other properties.
<?xml version="1.0"?> <shape xmlns="http://www.daa.com.au/~james/dia-shape-ns" xmlns:svg="http://www.w3.org/TR/2000/03/WD-SVG-20000303/DTD/svg-20000303-stylable.dtd"> <name>Circuit - Smily Face</name> <description>A smily face to brighten your day</description> <icon>smily.xpm</icon> <connections> <point x="0" y="4.5"/> <point x="13" y="4.5"/> </connections> <svg:svg width="3.0" height="3.0"> <svg:polygon points="0 0,13 0,13 9,0,9" style="fill: default" /> <svg:polygon points="2.5 1.5,3.5 1.5,3.5 2.5,2.5 2.5" style="fill: inverse" /> <svg:polygon points="9.5 1.5,10.5 1.5,10.5 2.5,9.5 2.5" style="fill: inverse" /> <svg:polygon points="6.0 4.5,7.0 4.5,7.0 5.5,6.0 5.5" style="fill: inverse" /> <svg:polygon points="1.0 4.5,3.0 5.5,6.5 6.5,10.0 5.5,12.0 4.5 12.0 5.5,10.0 6.5,6.5 7.5,3.0 6.5,1.0 5.5" style="fill: inverse" /> </svg:svg> </shape> |
The document element is <shape>. It has the following subelements:
| Subelement | Function | |
| <name> | The name by which this shape is known. | |
| <description> | A human readable description of the shape. | |
| <icon> | The Icon file associated with the shape, in this case the one you made earlier. | |
| <connections> | The connection points for persistant line connections. | |
| <svg:svg> | The actual shape information, built from further subelements which are geometric shapes such as polygons. |
Now you have a shape file describing your new template, and associating it with an icon. The last step is to inform the Circuit template group (sheet) that this shape has been added...
Now open Circuit.sheet with your favorite text editor. You'll
note that the document element is <sheet>, with several <description>
subelements, each of which gives a description in a different language.
It also has one <contents> subelement. That's where the rubber meets
the road, because <contents> contains many <object> subelements,
each of which describe a template shape. If your file has not been modified,
the first <object> will be named "Circuit - Vertical Resistor".
You're going to insert the smily object before the vertical resistor. Simply
copy the contents of the following box between the <contents> tag and
the first <object> tag:
<object name="Circuit - Smily Face"> <description xml:lang="no">En smilyface</description> <description xml:lang="fr">Une smilyface</description> <description xml:lang="de">Eine smilyface</description> <description>A smilyface</description> </object> |
The value of the name attribute of the <object> element must be spelled, capitalized and spaced exactly as shown. That's because that value is how Dia finds the shape file you previously created. In fact, this text must exactly match the <name> text in the shape file. Once you've completed this, quit Dia, restart it, and you should see the smily icon on the Circuit template. Click it, and drag on the drawing to make a smily. Connect zigzag lines to it, put it into a circuit. Save, quit, and see the results in XML. Within XML, experiment with changing the boolean value of the <attribute> elements whose name attributes are flip_vertical and show_background, and view the results in Dia.
This is XML at its best. You've just given an application a new capability, using only a text editor.
Allow your imagination to relish all the possibilities. Imagine how XML would help you write that app you always wanted to write but never figured out how. With XML, the only limit is your imagination.
Congratulations. You've learned as much XML as you can get from reading.
Now it's time to do. You've graduated. The next article walks you through
writing your own XML Hello World. Enjoy.
|
You spent some time with the Dia diagramming application to see how it wrote XML, and how it interpreted the XML changes we wrote to its files. You observed Dia as a benchmark for XML file design.
Then it was time to code. Starting with a "Hello World" DOM app, continuing with a DOM walker, and then building a DOM Document object in memory from scratch. You then wrote the code to write that DOM Document out to a file (actually to stdout) as XML. You accessed DOM elements and attributes by name.
YOUR "Hello World" SAX app quickly progressed to a SAX tree walker, then a SAX Explorer complete with a subclass of ErrorHandler, and finally SAX with per-record DOM Documents for a combination of small footprint and random access within each record.
You then thoroughly investigated DTD's, ending up with a methodology to build a DTD from an existing XML file.
So kick back and put your feet up. You did great. If you started out being intimidated by XML, you certainly aren't any more. You now have enough XML knowledge to quickly read and understand intermediate and advanced XML books, specification documents from standards bodies, and XML websites.
If an XML opportunity presents itself at work tomorrow, you can step forward with confidence. Sure, you don't know everything of XML. You know only a small part. But you've learned how to code XML, and more important you're going to learn where to find the additional information you need in order to do whatever XML task presents itself.
Read on...
We covered the tip of the iceberg. Just the basics of reading and writing XML from a program. There's a world of other XML knowledge to gain. There are excellent XML processing models besides SAX and DOM. Schemas offer an alternative to DTD validation. There's the entire discipline of rendering, complete with XSL, XSLT, and XML frameworks like Cocoon from Apache Software Foundation. There are specific XML varients such as SVG for vector graphics, as well as chemical and mathematical markup languages. There's even a markup language called XML-RPC for remote procedure control. And there's much, much more.
Luckily, the information is easy to find, and you now have the skills to exploit it. This article gives some web resources and a couple books that you'll find helpful.
Here are some URL's that will help you with specific projects. And we definitely covered enough so that computer programs you write can access and work with XML. Without the info in this tutorial, going farther would have been folly.But there's a world of other XML available to you:
Most XML books out there are trash. That's why I wrote this tutorial -- to undo the damage done by those so-called XML books that did nothing but scare would-be XML programmers out of XML, before they started. I assume that by this point in this month's Troubleshooting Professional Magazine, you understand that XML is anything but rocket science.
Yes, most XML books are trash. But in my travels I discovered some good ones, and one truly outstanding one.
The first 8 chapters are built quite a bit like this tutorial, with code progressions to walk you through the process of learning the principles. McLaughlin starts the reader on SAX, then walks you through creating, parsing and interpreting DTD's and Schemas, and finally giving a thorough indoctrination in DOM and JDOM. Chapter 12, "Creating XML with Java", is also necessary to basic XML programming. All the material is thorough and rigorous, with programs done in a Javanically compliant way.
From there he goes on to discuss all the Kewl things you can do with XML now that you know its principles, including XML publishing frameworks, XML-RPC, XML and Enterprise Java Beans, and finally business to business examples (think that might be a valuable skill?).
This is the book I would have written if I knew as much XML and Java as McLaughlin.
I don't say that lightly. In scope, depth, organization, and writing style, I find "Java and XML" quite similar to Samba Unleashed.
If you have anything to do with XML, even if you're not a Java person -- get this book!
One word of warning: "XML Processing with Python" is heavily weighted toward Pyxie XML methodology, and the utilities and tools on the CD aren't those you'd typically download from python.org. So if you want to learn generic XML, especially language independent, that's a disadvantage. BUT, if you're a Python guy (and most of us are whether we admit it or not), the tools that come with this book, ESPECIALLY Pyxie, can have you up and running with XML in record time.
When it comes to standards based specs, look what W3C has to offer. They offer the standard specifications for XML, XSL, XML Schemas, DOM, HTML, SVG (Scalable Vector Graphics varient of XML), Cascading Style Sheets. There's a working draft for XQuery -- a query language to extract info from XML docs. They have a working draft of the WAI -- the Web Accessibility Initiative. I've just scratched the surface. And best of all, these are *standards*. They won't be changed or kidnapped at the whim of a corporation.
As I researched for this month's magazine, it started looking like whatever W3C recommends, Apache Software Foundation builds or maintains. Sometimes the projects are initiated at corporations, but ASF has a reputation for running Open Source projects, so when the originators want to leave their project in good hands and move on to other things, they leave it to ASF. And of course, many ASF projects start at ASF. During the writing of this magazine, I saw so much kewl stuff from ASF that I almost forgot they're the source of the worlds most popular web server.
I'd like to take a quick look at just a few of the software tools you can download from the Apache Software Foundation website.
Near and dear to my heart is Xerces, the "parser" that made it possible to do this tutorial. The reason I put quotes around the word is Xerces can do things far beyond mere parsing. It contains the entire DOM interface, and all sorts of other things. And every bit of it works consistently, exactly like you'd expect it to. I had forgotten how much fun it is to work with software tools so solid you can spend your mental effort in design, rather than workaround. I used Xerces for Java, but there appear to be versions for C++ and Perl. And according to an email I just got, the Perl version now works with Linux.
Xalan is an XSLT processor for transforming XML documents into HTML, text, or other XML document types.
Cocoon is an XML framework. The way I interpret their description, you author your content in XML, which has no appearance component. There's then a logic component, which I don't understand, and finally an XSL component to map each XML entity to an appearance. The way I read this, the subject matter expert can write his content without having to worry about appearance. Obviously I don't understand the full picture. You might want to have a look yourself. It sounds mighty powerful.
What can I say about SOAP: :-) :-) :-). My understanding is that Microsoft originated SOAP, which is a lightweight data exchange mechanism for distributed computing. Now it's been submitted to W3C. IBM has implemented it, and as you can see Apache supports it. The way it looks to me, the community intercepted Microsofts pass and scored a touchdown.
Then there's Batik: Whoooaaa! This is a series of core modules to work with the SVG (Scalable Vector Graphics) XML dialect. Something very similar to the data format of Dia. Batik works with Java. Imagine being able to draw a picture in a Vector Drawing Program (vector drawings consume much less bandwidth than their bitmap graphics cousins), and have it visible in any browser with the proper Batik plugin! Ya know, I'm sick of creating diagrams in Dia and then having to tweak them in Gimp to show them to the world. I'm not saying Batik can do that yet, but it's what crossed my mind when I read what it is. The W3C tested six SVG implementations, including Adobe and JASC (the Paintshop Pro people), and Batik did exceptionally well in all areas except animation. See the results at http://www.w3.org/Graphics/SVG/Test/BE-ImpStatus.
So the next time you get an assignment in "new technology", your very first move should be to check W3C for a recommendation or working draft, and to check Apache Software Foundation for an implementation. After all, nobody wants to reinvent the wheel. And certainly we wouldn't pay a corporation for a reinvented imitation of the free wheel at W3C or ASF.
Another Leapster named Aaron Wadley took the time to tell me what he'd learned from some professional XML apps he'd done. Thanks Aaron!
A third Leapster, Scott Porter, chuckled and called me wrong when I expressed the opinion that it's easier to learn using Python than Java. Scott's a smart guy whose opinion you must take seriously, especially in matters of education. He's Dean of Business and Technology at the DeVry Institute campus in Orlando. So when I hit a brick wall with Perl::DOM, I investigated Java with an open mind, forgetting my experience writing a gui applet (the Symptom Description Wizard) before Swing existed. Scott was right. Java is a very straightforward, consistant language with a remarkably short debug cycle. I used Java to demonstrate XML, and the results speak for themselves. Thanks Scott.
A big thank you goes out to LEAP itself. LEAP has served as an incubator for so many of my ideas. LEAP is a parallel processing superbrain anyone can join. Thanks LEAP.
My wife Sylvia is a former grade school teacher. She's always told me the bottleneck in my teaching techniques is not telling the student what he's going to learn, then teaching it, then telling him what he learned. So I did that for every tutorial article in this magazine. Thanks Sylvia.
The Apache Foundation maintains the Xerces package, which includes validating parsers, DOM, SAX, and tons of other stuff. Xerces works right out of the .tar.gz, every time. It's what software should be. The Apache Foundation maintains many other astounding XML products, including the Coccoon XML Framework. Oh, and I guess I should mention that they maintain the most used web server software on the planet, Apache. Thanks Apache Foundation.
Where would we be without the W3C? What would we do without a solid, well written specification for what is and isn't XML, and what is and isn't DOM? I guess each year we'd use whatever definition the biggest commercial player happened to use that year. Thanks World Wide Web Consortium.
A guy named Brett McLaughlin wrote a killer book called "Java and XML". In any subject area Brett's writing, scope and depth would be exceptional, but in the XML world, where most books are useless, "Java and XML" can make the difference between learning and ignorance. Thanks Brett.
A big thank you goes out to everyone who has made the free software community what it is -- Richard, Linus, Eric, Maddog, Larry, Guido, Tim, and literally thousands of others.
Last and most, thanks to all you Troubleshooting Professional Magazine readers, for your critiques, suggestions, contributions and encouragement. This is truly your magazine.
My job is to see that adults get educated. In a world where technical learning obsoletes every 18 months, it's all too easy to fall off through the cracks. Especially if you're old, poor, or minority. This is one of the reasons I wrote "Rapid Learning: Secret Weapon of the Successful Technologist". And it's one of the reasons I'm so enthusiastic about Open Source and Linux.
College costs a fortune. Only slightly less are trade schools, corporate training courses, certification preparation courses, and even those self-guided courses on CD.
And then there's the bargain of the century, my Linux distribution. Just for today, don't think of it as an operating system. Think of it as a voluminous reference work and a killer computer lab, on a CD costing $29.00.
Let me ask you a question. You don't think I really knew all this XML information when I started writing this TPM issue 15 days ago, do you?
My Java was mighty rusty. No problem, the entire (voluminous) JDK documentation is contained in /usr/java/docs. I simply navigated to it with Konqueror, and looked up what I need. Sure, I could have gone online, but at 56K dialup, it sure is nice to have it on disk. Java books are great for learning Java, but when it comes to a class and method reference, nothing beats the JDK docs that come on your Linux distro.
I knew DOM pretty much by heart, but nothing else. SAX? Not a bit. DTD's? I knew their purpose, and I had some books giving partial syntax that wouldn't validate anything, but I'd never used it. Oh, and my Java was mighty rusty. Using my Linux distro, the Internet, and my Rapid Learning Process, I learned almost as fast as I could write.
Try the following command:
$ find /usr -type f | grep -i xml | lessI found literally hundreds of files, many of which contained valuable XML information. I found docs on the SAX functions for Gnome, parsing info for QT, and for KDE's KXMLGUIBuilder, KXMLGUIClient, and KXMLGUIFactory classes. I found the XML functions for PHP.
But the educational value of a Linux distro goes far beyond Java and XML. Try some of the following:
| Subject | Command | |
| DNS | find /usr -type f | grep -i named | less | |
| Samba | find /usr -type f | grep -i samba | less
find /usr -type f | grep -i smb | less |
|
| Apache | find /usr -type f | grep -i apache | less
find /usr -type f | grep -i httpd | less |
|
| Java | find /usr -type f | grep -i java | less | |
| C++ | find /usr -type f | grep -i c++ | less
find /usr -type f | grep -i gcc | less |
|
| Perl | find /usr -type f | grep -i perl | less | |
| Python | find /usr -type f | grep -i python | less | |
| LDAP | find /usr -type f | grep -i ldap | less | |
| SSL | find /usr -type f | grep -i ssl | less |
Your Linux distro pays for itself many times over as a reference. But wait, there's more! If you order your Linux distro now, you also get...
A computer lab! That's right, a UNIX workalike where YOU have the root password. I ask myself how far I would have gotten trying to learn web serving, TCP/IP, DNS, sockets, and the like without Linux. The answer is self evident. I've been in "IT" for 17 years, but until I got my first Linux distro in November 1998 I had to ask my network administrator how to solve connectivity problems. Now I can solve my own problems (and other people's too).
But what about Java XML? Java and Xerces are available on Windows. Why didn't I use Windows?
In a word, BSOD (Blue Screen of Death). When I'm learning, I have enough variables to consider without having to worry if what I'm seeing is a result of an operating system quirk, rather than a facet of the technology under investigation. Technology just seems to work as advertised on Linux. That can't always be said of Windows.
Then there's the issue of democratization of education. Doesn't it seem like proprietary software is like the camel -- first his nose is in the tent, and then the whole camel is in the tent. Theoretically Windows is cheap, but somehow it always ends up sucking up big bucks. Once you buy your Linux distro, your spending days are over, but your learning days have just begun. And oh yeah, you can run Linux on cheaper hardware. We recently inaugurated a president who many refer to as "the education president" -- a man constantly campaigning for the democratization of education. Could it be that Linux is now politically correct?
So the next time one of your Windows buddies refuses to look at Linux, try a different approach. Tell him for $29.00 he can get a CD to teach him how to get ahead in the Windows world, and how to do better on his certification tests. Tell him that CD is a wishing well -- wish to know anything and he can find it there. Just don't tell him it's Linux.
The days of throwing money at education hoping it will somehow improve are over. We heard it the other night. These are times of accountability in education. In the spirit of the day, if the certification mills and the colleges can't do the job, people must have an alternative. A Linux distribution CD is part of that alternative. And it's so affordable vouchers aren't necessary.
By submitting content, you give Troubleshooters.Com the non-exclusive, perpetual right to publish it on Troubleshooters.Com or any A3B3 website. Other than that, you retain the copyright and sole right to sell or give it away elsewhere. Troubleshooters.Com will acknowledge you as the author and, if you request, will display your copyright notice and/or a "reprinted by permission of author" notice. Obviously, you must be the copyright holder and must be legally able to grant us this perpetual right. We do not currently pay for articles.
Troubleshooters.Com reserves the right to edit any submission for clarity or brevity. Any published article will include a two sentence description of the author, a hypertext link to his or her email, and a phone number if desired. Upon request, we will include a hypertext link, at the end of the magazine issue, to the author's website, providing that website meets the Troubleshooters.Com criteria for links and that the author's website first links to Troubleshooters.Com. Authors: please understand we can't place hyperlinks inside articles. If we did, only the first article would be read, and we can't place every article first.
Submissions should be emailed to Steve Litt's email address, with subject line Article Submission. The first paragraph of your message should read as follows (unless other arrangements are previously made in writing):