Troubleshooting Professional Magazine
|
The Many Faces of Troubleshooting and Problem Solving |
| The mere formulation of a problem is far more often essential than its solution, which may be merely a matter of mathematical or experimental skill. To raise new questions, new possibilities, to regard old problems from a new angle requires creative imagination and marks real advances in science. - Albert Einstein |
| trou·ble·shoot also trou·ble-shoot
(trbl-sht). v. trou·ble·shot (-sht), trou·ble·shoot·ing, trou·ble·shoots. v. intr. To work or serve as a troubleshooter. v. tr.
Source: The American Heritage® Dictionary of the English Language,
Third Edition trouble-shoot v : solve problems; trou·ble·shoot·er also trou·ble-shoot·er
(trbl-shtr).
1.A worker
whose job is to locate and eliminate sources of trouble, as in
mechanical
Source: The American Heritage® Dictionary of the English Language,
Third Edition troubleshooter n : problem solving n prob·lem (prblm)
1.A question
to be considered, solved, or answered: math problems; the problem of
how
to
Source: The American Heritage® Dictionary of the English Language,
Third Edition |
|
|
Basically, troubleshooting and problem solving are the same thing. They both relate to solving problems. The word "troubleshoot" tends to be used more for repair of well defined systems (as implied in the references to "mechanical" devices), or in human disputes. But really, according to the dictionary they're both the same thing, and can apply to well defined systems (systems with a known and documented "as designed" state and behavior), or fuzzily defined systems without a known or documented "as designed" state and behavior.
The generality in definition has led to some interesting choices and mischoices in the hiring of consultants and expert trainers, as well as the adoption of methodologies to "solve problems". The good choices have spawned success, while the mischoices have failed and been labeled "program of the month".
I'm not immune to making mischoices. Although I have, for years, steadfastly defined my brand of Troubleshooting as "The act of restoring a sub-performing system back to its as-designed state", and alternatively (as used with Bottleneck Analysis) "The act of improving the performance of a system beyond its as-designed state", several times early in my career I made the mistake of selling it to those needing to solve problems in "systems" lacking an "as designed state". You know, business problems, human relationships and organizational issues and the like.
And of course, I've seen folks sell generic problem solving courses to those who needed to "restore a sub-performing system back to its as-designed state" -- an equally bad mistake.
In both cases, desire for revenue partially accounted for such mistakes. But not entirely. The different types of problem solving, and the distinctions between them, are obvious only after considerable thought, even to experts.
This issue of Troubleshooting Professional Magazine discusses the various types of problem solving (and troubleshooting), the distinctions and the root differences between types of systems, and the problem solving methodologies optimized for those types of systems. Be sure to see the article titled Cars and Tanks, which asserts by analogy the point that although generic problem solving methods CAN be used to solve well defined problems, doing so is suboptimal.
If you're a Troubleshooter or Problem Solver of any type, this issue of TPM was made especially for you.
Also, we're having our first annual Troubleshooting Professional
Magazine
trivia contest. Simply name the issue (by year and month) and article
names
for the ten different articles containing the these ten phrases:
|
Anyone answering all 10 correctly will be mentioned in the January 2001 issue, and if they'd like, will have an email link and an http link from the 1/2001 issue. If nobody gets all 10, the person with the most correct will get their name, and if desired email and/or http links.
| dis·tinc·tion (d-stngkshn) n. 2.The condition or fact of being dissimilar or distinct; difference: the crucial distinction between education and indoctrination (A. Bartlett Giamatti). See Synonyms at difference. Source: The American Heritage® Dictionary of the English Language, Third Edition |
|
|
You might wonder why I don't use the word "difference" instead of
"distinction".
It's an issue of connotation, not definition. Use of the word
"difference"
usually focuses attention on the two entities being compared. Use of
the
word "distinction" focuses on the difference. In other words:
|
Difference:
|
4 > 3 | |
|
Distinction:
|
4 > 3 |
"Distinction" is more of an entity in and of itself, which is what we want for many of the explanations that follow. In many types of mental activity, the key to mastery is understanding the distinction, not just the two items being contrasted.
Analyzing the solved state is basically asking "how would you like things to be", followed by inductive reasoning to formulate a system that can deliver those results. Also included is design work in actually realizing the conceived solved state. Because design and inductive reasoning requires much more creativity, analyzing the solved state requires quite a bit of creativity (and therefore quite a bit of brainpower to supply that creativity). Remember this point.
Sometimes only one of these two steps is required. In fixing a machine, the solved state degenerates into "the as designed state and behavior". No analysis, induction or creativity needed. This point will be made time and again throughout this issue of Troubleshooting Professional.
Likewise, analyzing the problem state is sometimes not necessary, as pointed out by problem solving expert Fred Nickols (link in URL's section). Fred points out that sometimes it's impossible to return to the pre-problem state anyway, so analyzing the problem state is a needless exercise. As an example he points out the stock market crash of 1987, and the fact that though the crash caused many problems, the crash could not be undone.
Perhaps a more common example of irrelevant problem state occurs in problems created by progress. When the free Linux operating system acquired a power level comparable with UNIX, many UNIX vendors went out of business. The UNIX vendors were still operating as designed, but now they were in an environment hostile to that design. No amount of assigning cause would make the UNIX vendors profitable. Only a new solved state would do that.
Most advocates of general problem solving methodologies make additions to the two steps of analyzing the problem state and analyzing the solved state. Many include a step or substep that could be called "how do we get there from here?". In other words, how do we move from our present condition to the solved state? Oftentimes that requires co-worker support, management "buy in", a budget, and much, much more. It's not simple.
Another frequently added step is "how do we prevent future problems?". That can be either future occurrences of the same problem, problems caused by the solution, or even brand new problems. So a possible generic problem solving process could look like this:
| 2. Get a complete and accurate symptom description 3. Make damage control plan 4. Reproduce the symptom 5. Do the appropriate general maintenance 6. Narrow it down to the root cause |
Most experts have an extremely complex methodology for determining the desired solution. It's tough to jump-start creativity.
So we have an interesting distinction in problem solving. Some systems have a documented as-designed state and behavior -- typically machines, computerized systems and networks. The desired solution in such systems degenerates to the restoration of as-designed state and behavior. No inductive solution finding is necessary. Several problem solving methodologies are optimized for systems with defined and documented state and behavior. Those methodologies produce ultra-fast solutions because the Troubleshooter doesn't waste his time doing steps whose purpose is to creatively determine the solved state, which in this case is already defined.
I choose to call systems with a defined and documented state and behavior "well defined systems". I choose to call systems without a defined and documented state and behavior "fuzzily defined systems". System definition is not a binary absolute, but rather a spectrum. On one end are machines designed by humans, with complete schematic diagrams. Everything about the system is known. Simple to moderately complex machines, and extremely well documented computer programs are great examples.
On the other end of the spectrum is the human mind, which is probably the most erratic, unpredictable and variable system imaginable. Any documentation of the human mind, or relationships between small number of people, is a matter statistics at best, or conjecture and anecdote at worst. When dealing with the human mind or relationships between a few people, solutions are almost completely creative in nature -- it's just too hard to deduce a "root cause". This is especially true in relationship disputes, where each party assigns causation to the other :-)
Human physiology is somewhere in the middle. It's absolutely documented and defined that a human without a liver or a heart will soon die. It's absolutely documented and defined that the organ used to see is the eyes. At the most general level, doctors and physiologists can draw a very accurate block diagram of a human. But when it gets down to details like the effect of hormones on various systems in the body, the definition goes way down, once again supported by statistics and anecdotal evidence. To the extent that human physiology is well defined, the "fix" is to restore the bad "part" to its as-designed (or in this case normal) state. At lower levels where physiology is fuzzily defined, much creativity is necessary to fix symptoms with a minimum of side effects.
Somewhere between human physiology and simple machines are complex mechanisms like computer operating systems. Although the point could be made that an operating system is completely documented by its body of source code, the fact is there's no human capable of knowing that whole body of source code. Therefore, its level of definition depends on block diagrams and other documentation. Some operating systems are more predictable and straightforward than others. UNIX and most of its workalikes (Linux included) are fairly modular, lending themselves well to rather complete documentation of state and behavior. The Windows operating system, on the other hand, is rather non-modular and unpredictable, so that at many levels it is not well defined in spite of the fact that it was built by humans and its entire body of source code exists.
Somewhere between human physiology and the human mind is the human organization. Humans are like gaseous material -- the more of them there are, the more predictable (deducible) they become. The existence of rules and policies make them even more predictable, in some cases to the point where they can be accurately modeled. Human organizations can be documented, defined and modeled when mixed with machines, technology and policies, such as in a factory. This is one of the reasons for the extraordinary success of the Theory of Constraints in the manufacturing sector.
So to solve problems, the level of definition defines whether it's necessary to analyze the problem state, the solved state.
Within the reproducibility distinction, there's a sub-distinction consisting of whether intermittence is caused by fuzzily defined system (example: the Windows operating system), or a well defined component whose malfunction happens to vary with time, temperature, stress, distortion, etc. (a thermally intermittent transistor is an example). They are both very difficult to solve. The latter is usually soluble given sufficient time. The former often is not. They're both troubleshot approximately the same way, so this is the last we'll say about this sub distinction.
The most effective weapon against intermittence is maintenance, both preventative (proactive: before the fact) and repair-consequent (reactive: after the fact, called General Maintenance in the Universal Troubleshooting Process). Intermittence is often caused by worn, dirty or bent connections between components, rather than components themselves. Such non-component causes are harder to find by normal deductive reasoning, but they're a primary target of maintenance. Repair consequent maintenance is forbidden and extremely dangerous in safety critical situations, but preventative maintenance is acceptable and necessary in safety critical situations.
Because maintenance is such an effective weapon against intermittence, those problem solving methodologies emphasizing maintenance are most effective against intermittence. The champion here is the Intelliworxx Era 4 troubleshooting tool, which raises repair-consequent maintenance to an artform. The Universal Troubleshooting Process also places emphasis on repair-consequent maintenance, having it as step 5 of the process (General Maintenance).
The Root Cause Analysis problem solving methodology contains a step called Barrier Analysis, which examines barriers to failure. Certainly preventative maintenance, and the policies and procedures that support it, is a major barrier. Though not specifically named in Root Cause Analysis, preventative maintenance is obviously a major part of that methodology.
As a matter of fact, intermittence seldom survives Root Cause Analysis. Besides its emphasis on preventative maintenance, Root Cause Analysis demands the finding of the true root cause. For instance, a power plant's reactor tripped because of a bad power supply board, but what was wrong with the board? The board had a bad solder joint, but why did that bad solder joint happen? The solder joint occurred from constantly elevated temperatures in the room, but why were the temperatures high? The temperatures were high because one of the room's air conditioners had conked out, but why wasn't that fact discovered before it caused damage. The fact wasn't discovered because there was no reporting procedure for temperature in the room. So ultimately, lack of a procedure to report the room's temperature tripped the reactor. Once the procedure is put in place, the air conditioner is repaired or replaced, the solder joint is resoldered, and the reactor is put back on line, it will never happen again. Well, except that my simplification forgot to follow the fault tree down the air conditioner to find why it failed, but assuming you follow that fault tree too, you can be pretty sure that failure mechanism will never occur again.
Contrast this with the repair of consumer equipment, where the solder joint itself is considered the root cause. If that stereo is returned to a hot room...
Most evident, the repair-consequent maintenance that speeds repair so much in non safety sensitive systems can kill in safety sensitive systems. I have no idea how nuclear defense systems work, but imagine an armed missile goes into launch sequence and fortunately is manually disarmed. Would you go in and clean all switches and controls?
Not likely. Let's say cleaning those switches and controls fixed the problem because the problem was a dirty switch. You don't know which switch. You don't know what caused it to get dirty. You never will. You just erased the evidence. Some day that switch or another one will get dirty, a missile will go into launch sequence again, and maybe, just maybe, nobody will shut it down in time. No repair-consequent maintenance is acceptable in extreme safety sensitive situations.
Another obvious difference in the treatment of safety sensitive systems is that you don't try to reproduce the problem. It would be just a little too gutsy to try, for instance, to reproduce the missile's spontaneous launch sequence initiation, thus placing the world within a minute of nuclear war. Incidentally, this is sort of what happened at Chernobyl. The technicians wanted to investigate the system's behavior in the absence of various safety mechanisms, so they defeated those safety mechanisms.
And then there's the fact that in extreme safety sensitive systems, the term "root cause" has an entirely different meaning, as illustrated by the discussion of the power plant in the preceding section of this article. Also, in extreme safety sensitive systems, one never dismisses an apparently disappeared intermittent with "it's probably fixed". Consumer testing is wonderful for televisions, but not for jumbo jets.
Between the extremes of battery powered radios and nuclear defense systems are a wide spectrum of systems whose problem solving methodologies represent a tradeoff between the cost effectiveness and safety.
Bad car brakes can kill, but nobody would spend the thousands of dollars it would take to trace a lone event of brake failure. Instead, symptom reproduction is attempted, repair-consequent maintenance is done, and finally a non-rigorous analysis is done of likely causes, and all implicated parts are replaced. This is half way between what would be done with a battery operated radio (sorry, we can't reproduce the symptom), and a nuclear power plant (full Root Cause Analysis).
Inadequacies don't just happen in machines and technology:
Using one problem solving methodology, for all categories of problems, would be like building houses using only a hammer. In this competitive world, for each type of problem solving you do, you need a problem solving methodology optimized for that category of problem.
The good news is once you've learned one, the rest are easier to learn. They all have commonalties.
In spite of the differences between systems and their associated methodologies, there are remarkable similarities between the methodologies. After learning one, it's likely that learning others will be significantly easier. That's a good thing, because it's likely the expert problem solver will need multiple methodologies because he solves multiple problem categories.
When safety concerns permit, we often ignore sparse intermittents. How many invoices come back "could not reproduce problem". But in an electric power station, to name one example, future occurrence must be prevented. And that means finding the root cause.
Root Cause Analysis is a troubleshooting process optimized specifically for sparse intermittents. Max Ammerman, formerly of Florida Power & Light, literally "wrote the book on the subject". His book is called "The Root Cause Analysis Handbook". This 135 page book is certainly not simple, but it's understandable by a person who solves problems for a living, especially if he's studied any other problem solving methodology.
In the introduction, the book describes Root Cause Analysis as using the following process:
In fact, every chapter offers hints, tips, guidelines and pitfalls. He even tells you exactly how to interview a person, how to avoid "leading" him, and what to do if the person appears to be hiding something (a likelihood when interviewing someone about a serious messup). It's the little "how to" explanations that make this book so useful.
Task analysis it the act of analyzing the task related to the event. Task analysis reveals how the task should be done, as a baseline to evaluate what actually happened.
Change analysis is the comparison of the activities during or leading up to the event, contrasted with those same activities done successfully. The trick here is to ask questions leading to distinctions. These distinctions prove useful in later steps.
Control barrier analysis is the study of failed control barriers. A control barrier is anything, be it physical, policy, or anything else, that prevents problems. Either the existing control barriers are insufficient and need augmentation, or a control barrier failed to prevent the event. In the latter case, evaluate what caused the control barrier to fail. It's absolutely vital you identify all control barriers.
Event and causal factor charting is the creation of a flow chart detailing all the activities before, during, and after the event, as well as conditions, changes, control barriers. The idea is to trace the cause and effect back to the various causes, so that in a later step a root cause can be correctly identified. This step is complex, so read chapter 5 carefully.
We all think we know how to conduct interviews. Chapter 6 goes over the process with a fine tooth comb. Many times during the chapter, I thought to myself "that's a good point -- I didn't think of that". The final work product of the interview is an interview sheet and an observation sheet. These are used to reveal and to substantiate hypotheses necessary to finish the Root Cause Analysis.
Determining the root cause is where the rubber meets the road. A wrong root cause will doubtlessly create a flawed solution, at best a "coathanger" solution fixing a symptom but creating or allowing side effects. At worst it will simply not work, or make things worse. In this respect Root Cause Analysis is identical to the Universal Troubleshooting Process. Chapter 7 discusses how to put together all the info gleaned earlier to correctly deduce the root cause.
Developing corrective actions requires knowledge of the root cause, failed barriers, distinctions between functional and dysfunctional tasks, economics, company policies, government regulations, and a host of other information. In the terminology of generic problem solving, this step analyzes the solved state.
The final work product of the Root Cause Analysis is the report. It must give conclusions and recommendations, and must be presented correctly.
Root Cause Analysis is vital for sparse intermittents, and for safety critical situations where letting the problem recur or reproducing the problem is out of the question. It's an excellent tool for the diagnosis of failed processes, policies, even human interactions. When you read this book, be aware that it mentions PIC without ever defining it. PIC stands for Problem Identification & Correction, Florida Power & Light's internal name for the Root Cause Analysis process.
If you solve problems, you need to know Root Cause Analysis. Max Ammerman's book is called "The Root Cause Analysis Handbook", ISBN 0-527-76326-8. It's widely available. Get it.
Bottlenecks leave clues. Put a 40 watt, a 100 watt and a 150 watt lightbulb in series, and only the 40 watt bulb lights. The clue is that it's got most of the voltage, so it lights up. On the factory floor, the bottlenecked machine or process has a huge stack of inventory awaiting work by that machine or process. And on a long trail too narrow for people to pass, the slowest person has a huge space in front of him :-)
Sometimes the bottleneck's clues must be uncovered. In a computer, you need software to display the memory and CPU usage in order to see if either is bottlenecking your computer. Any suspected bottleneck can be tested by reducing its throughput and seeing if system throughput decreases commensurately. For instance, if you don't know whether your network is the bottleneck, slow it down either by adding traffic to it, or by decreasing its bits per second figure. If your computer programs slow commensurately, that's the bottleneck. Otherwise not. In computer programs for which you have source code, you can sometimes temporarily comment out a suspected bottleneck and see if the program speeds up significantly. Or you can add a delay to it and see if the program slows commensurately.
The theory of constraints doesn't stop with finding the bottleneck. It offers alternatives on how to "fix" the bottleneck. Of course the most straightforward way is to add capacity to the bottleneck. Buy a faster CPU. Add another drillpress and operator. Switch from 10mb to 100mb Ethernet. Get a faster modem. Hire more salesmen.
Adding capacity to the bottleneck can be a great solution. But it's often expensive, especially in cases like the microprocessor where you need to replace, rather than add to, the resource. Luckily there are other ways to "fix" a bottleneck. One of the easiest is to make sure the bottleneck is running full blast all the time. If it's a machine in a factory, make sure it runs three shifts, make sure its operator does nothing but run that machine, and make sure upstream machines supply it with parts as needed, with an adequate stockpile so it can continue through those inevitable variations that crop up. In an audio amplifier, make sure the power supply runs full blast all the time by putting huge capacitors across the DC so that when the music is soft, the power supply goes full blast charging that capacitor, which is then discharged when loud music sucks out more electricity than the power supply can produce.
OK, so it's running full blast and it's still not enough. Often you can offload some of the bottleneck's work to a non-bottleneck. If you read "The Goal" by Eliyahu M. Goldratt and Jeff Cox, you know you can get a fast guy to carry all of Herbie's (the slowest guy on the march) equipment. You can get a less efficient machine to process the parts instead of the bottleneck, or even outsource the processing. Sure, it's expensive, but remember, the increased expense is only for that one process, but because it's the bottleneck, the one-process investment increases throughput for the entire system. Perhaps the coolest example of offloading is cache memory in a computer. Dynamic memory, the only kind cheap enough to use in quantity in computers, is unacceptably slow. It's the bottleneck. So computer designers long ago learned to offload most of the dynamic memory's work to the CPU, which must synchronize dynamic memory's contents with a small, fast and expensive static ram Cache memory. For each memory access, the CPU decides where to go for it, and if the accessed memory is not in cache, places it there, getting rid of what the CPU calculates is the most dormant data in the cache.
Whew, that CPU has to work. But because it's not the bottleneck, by definition it has excess capacity available. The result of memory caching is that up to 90% of the time, the CPU doesn't need to go through the slow process of requisitioning data from dynamic RAM. On Windows computers, you can have the CPU offload some work from the hard disk. Obviously disk cache does that, but in Windows there's a subtler way. If you have a fast processor (or a slow disk) you can speed system throughput by using disk compression. Sure, the CPU must work overtime compressing and uncompressing those files, but the resulting disk reads and writes are smaller. Given that disk access could be 100 times slower than memory access, those smaller reads and writes increase system throughputs. So unless your CPU is already close to overworked, disk compression speeds system performance.
Sometimes the bottleneck busies itself doing unnecessary work. In a factory, maybe some of the parts put in the oven don't really need the heat treatment. Or maybe, because there isn't an inspection station right before the bottleneck, bad parts are going into the bottleneck, displacing potential good parts. Or maybe downstream people and processes are ruining parts that came out of the bottleneck. All these sources of unnecessary work can be corrected.
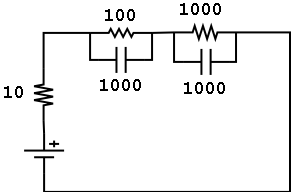
The theory of constraints tells us there are many ways to "fix" a bottleneck. But so far what I've described is just bottleneck analysis on steroids. The theory of constraints goes much farther. As an introduction, let's discuss the difference between compressible and incompressible systems.

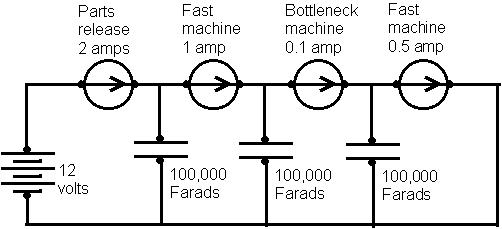
But you can make it a compressible circuit by adding a 1000mfd
capacitor
across each resistor. Now, upon initial closure of the circuit, the
capacitors
take every bit of current the battery can supply. They "build up
inventory",
if you will. Early in the stabilization process, the voltage across
each
capacitor is based on the amount of DC current that's "flowed" through
it, meaning each cap has the same voltage. So early in the
stabilization
process the 100 ohm resistor will conduct 10 times the current
conducted
by the 1000 ohm resistor. As things continue, the slower flow through
the
1000 ohm resistor results in a greater voltage across its capacitor,
meaning
that the current discrepancy starts to disappear. When things reach
steady
state, once again the battery and resistors pass identical current.
That's similar to a factory. Each machine has room for a stockpile in front of it. Each stockpile is like a capacitor. It can grow and shrink. And in a factory, you can always increase the stockpile potential by adding space, or even warehouse space. It's like adding capacitors while a circuit is running. Another difference between a factory and a circuit is that machines are not like resistors. A resistor conducts more as the pressure on it increases. Not so a machine. A machine either runs at its rated throughput, or if it runs out of incoming parts, less. But having a huge stockpile does not increase the throughput of the machine. So electronically, a factory machine would be modeled as a constant current source, not as a resistor.
The final difference between the factory and the circuit is one of degree. Stockpiles resemble 100 kilofarad capacitors in a 1 amp circuit -- they can take a month or more to "fill up".
Calculations *VERY* approximate, I=dQ/dt and Q=CV |
And they exhibit little or no loss during the month. That's very hard for an electronics person to wrap his mind around. But that's what it would take to model a factory. From here on we'll discuss the factory in factory terms.
Released raw materials are "pushed" into the system, after which each machine "pushes" materials to the next. In a factory, order counts. Everything upstream of the bottleneck can be functioning at breakneck speed, while everything downstream of the bottleneck is starved. Order becomes more significant when combined with the deadly duo of dependent events (cascaded stages in a process) and statistical fluctuation (variation).
Take two machines, with the faster machine four times the throughput of the slower. If the slower machine feeds the faster machine and the faster machine goes down for an hour, there is no lost production. The slow machine simply builds a stockpile for the fast machine. When the fast machine comes back on line, it makes quick work of that stockpile because it's four times faster than the slow machine.
Now reverse the machines. The fast machine feeds the slow one, and the fast one once again breaks down for an hour. Let's say that after 1/4 hour the slow machine finishes its stockpile of incoming parts. Now it has to wait for more parts from the fast machine. Now there's lost production in the amount of 3/4 of the slow machine's hourly throughput. Remember, the slow machine can't "catch up" the way the fast one can. The only way to have prevented that was to keep a continuous stockpile in front of the slow machine equal to the worst case downtime throughput of the fast machine.
This isn't especially impressive with just two machines. But if a factory were unfortunate enough to be cascaded with machines sorted fastest to slowest from upstream to downstream, the requisite stockpiles in front of each machine would be enormous. Those stockpiles represent money spent but not recovered from customers. They represent potential obsolescence. They represent a mess making it harder to work in the factory. They represent storage costs. They can drive you to the poorhouse.
On the other hand, a factory fortunate enough to have the slowest machine at the beginning would require no stockpiles. Every other machine could "catch up" to the slowest machine's pace if something in front of it went down.
But the bottleneck is seldom at the front. So the theory of constraints presents methods of calculating material release so that the bottleneck always has a stockpile of incoming parts.
It gets even more complex. Typically the bottleneck machine will process several different types of parts. The different parts are destined to go into finished products in different customer orders, each of which must be delivered on time. How do machines upstream schedule delivery of appropriate parts to the bottleneck such that those parts contribute to ontime delivery. Remember, the bottleneck must run continuously at full speed. Among other things, that means minimal parts changes (each parts change requires a setup). In other words, for a given incoming part, process all of that part in the incoming stockpile. Or at least enough to satisfy all current orders.
In the name of (false) efficiency, some folks extend the "long run" philosophy to non-bottlenecks. The result is that the bottleneck is starved for certain needed parts, because the upstream processes are creating excessive numbers of a different part. So one order ships late, and excessive inventory in the long run part are developed.
The trick is to use shorter runs on the non-bottleneck machines. After all, by definition they have excess capacity, so they can afford to be idled by extra setups. Meanwhile, the shorter runs on non-bottlenecks means a more even parts distribution arrives at the incoming stockpile of the bottleneck, so it can fulfill orders.
But wait, there's more. As taught in the Universal Troubleshooting Course, bottleneck analysis is all about speeding up bottlenecks, which are considered bad. But in the Theory of Constraints, bottlenecks can be useful. Think of your car. It would continuously go 120mph if you didn't have a bottleneck called "the accelerator" to slow system throughput (via fuel delivery). The theory of constraints endeavors to minimize stockpiles by calculating the release of raw materials at a time such that they will arrive (as part of finished goods) at the shipping dock just in time for ontime delivery to the customer. They USE the bottleneck to calculate the time from parts release to shipping dock, and can even use it to calculate parts orders and promise dates to their customers. It's the bottleneck that allows them to accurately calculate these things.
Trickier still, there are situations in which throughput is significantly slower than the bottleneck. The classic example is the fixed speed streaming tape drive, which must be supplied with sufficient data to fill the tape passing the tape head. If the streamer moves faster than the data supply feeding it, many streaming tape drives cannot simply stop. There's a finite time until they've stopped, after which they must reverse and re-cue before recording more data. Depending on the mismatch between the tape and the data flow into it, this constant "shoe shining" could cut the theoretical capacity of the bottleneck by several fold. In fact, such inefficiencies happen in any system where a component has speed and inertia. An assembly line comes to mind. If the line is sped up beyond the capacity of a specific nut tightener to tighten his assigned nut, he must either skip certain units and put them aside, pass them on creating rework down the line, stop the line, or some equally counterproductive action. True assembly lines, as opposed to cascades of stations with stockpiles, react very badly to oversupply of incoming material.
So you've eliminated some bottlenecks, eliminated excessive supply to the existing bottlenecks, and exploited bottlenecks to schedule orders. Now you're running a phenomenally smooth factory. But as you continue to further enable the bottleneck, there comes a time when you seem to have many roving bottlenecks, even though calculations indicate that these roving bottlenecks have more than enough capacity to supply the bottleneck, and indeed the order flow.
Here's what's happening. As the bottleneck approaches the throughput of certain other machines, those machines are no longer able to "catch up" when inevitable upstream variations deplete their stockpiles. So they don't move needed parts to the bottleneck in time, and there's lost production. Basically, everything's running too close to "the edge". The solution is to release parts early enough to maintain non-bottleneck stockpiles big enough to cover any expected upstream downtime.
And of course, if the bottleneck's throughput continues to be improved, you reach a point where another machine becomes the bottleneck. It's very important to recognize that change, and continue your calculations using the new bottleneck. And remember, sales can be the bottleneck (meaning the factory as a whole has excess capacity). That's the time to acquire new customers and get more orders from the old by promising the delivery times that your excess capacity can provide.
Whew! Quite an explanation, and it barely scratched the surface. Luckily, Eliyahu Goldratt and Jeff Cox have written a book on the Theory of Constraints called "The Goal" (ISBN 0-88427-061-0). I've read it probably once a year for the past 5 years, and it's my favorite book. The Goal has a "can't put it down" plot, in which characters we can all recognize (some we can identify with, and some we recognize as enemies) blunder through life slowly learning the lessons of the Theory of Constraints. By the end of the book they're Ninjas, and the reader has learned right along with them. There are good guys, bad guys, good guys who are forced to be adversarial by circumstance, love and plenty of conflict. I'm a Stephen King fan, and I can tell you that "The Goal" is every bit as exciting as the best of King's books.
But by far the most memorable parts of the book are the ingenious analogies Goldratt and Cox use to demonstrate the complexities of factory logistics. One, a boy scout hike, uses a boy named "Herbie" as a metaphor for a bottleneck. Every time someone slows down in front of him, he has to stop, but when the faster boy in front of him sprints to close up his own gap, Herbie can't catch up, so he falls ever more behind, opening a huge gap in the line. Putting Herbie at the front eliminates all gaps, and allows the group to progress at Herbie's maximum speed. They then offload work from Herbie the bottleneck by carrying the heavy stuff in his backpack, and the whole line sped up. "Herbie" probably has more name recognition than many state governors.
The second well known analogy from the book is "the match game". It's a game invented by the hero to model the effects of the combination of dependent events (cascaded steps in a process) and statistical fluctuation (variation). By the time you're done with the book, you can do more than understand the principles. You can do more than recite the principles. You can FEEL the principles. And if your experience is like mine, every time you read the book you obtain a greater level of understanding and feeling.
I recommend that everyone who ever solves any kind of problem (and who isn't included in that definition) read this book. At $20.00 for the book and maybe 10 hours to read it, the learning to investment ratio is right off the charts.
It won't work, of course. And the main problem won't be the ensuing morale problems, or even turnover. The problem is that very few of the fired employees contributed to the root cause of the company's problems. Very few of them contributed to the company's bottleneck. Sadder, some of the fired employees might be among the company's best. How can that be?
Everything has variation. Some of the variation has a cause, and some is statistically insignificant "random noise". With extreme amounts of employee variation, all the variation could be random noise. In other words, the worst guy this year could be the best guy next year, in spite of the fact that nobody changed what they were doing.
To find out whether a particular person's performance is
statistically
significant, you do some statistic evaluations on the performance
figures
to obtain an Upper Control Limit (UCL) and a Lower Control Limit (LCL).
All performances between the upper and lower control limits are
considered
normal performance, not subject to any discipline, correction or
awards.
Anyone above the UCL should be evaluated to find out what he's doing
right,
so everyone can do the same thing. Anyone falling below the LCL should
be, for lack of a better word, troubleshot, to find out what is going
wrong
with his performance. There are cases where this statistical analysis
revealed
that the employee needed a new eyeglass prescription, and in fact once
the new eyeglasses were obtained, the problem vanished. Below is a
cartoon,
based on a control chart, lampooning those who would "grade on the
curve"
in a corporation:
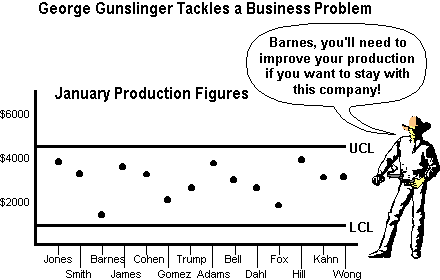
The gunslinger is making a fool of himself because all employees,
including
Barnes, are within the statistical limits, thus none of them is the
cause
of any company problems, and the company cannot be improved by getting
rid of, or tampering with, any one of them. If the gunslinger wants to
improve productivity, he must look at the production system common to
all
those employees.
The process of assigning causation through statistical analysis is called Statistical Process Control (SPC). This was W. Edwards Deming's starting point. It's an extremely powerful tool. SPC isn't used only to evaluated the performance of people. It can evaluate anything that can be expressed numerically. Basically, when any given "thing" falls outside of the UCL/LCL borders, it should be investigated and either fixed or propagated, as appropriate. Notice that this bestows the opportunity to answer the question "why was this month so good" (of course after determining that the months figures were above the UCL). That answer can then be used to make permanent improvements.
So SPC first alerts us to problems, and then gives us some tools to diagnose those problems. Note that at any point in the investigation we can move from SPC to a diagnostic process like the Universal Troubleshooting Process, Jim Roach's Diagnosis, the Six Step Loop, Root Cause Analysis, or Theory of Constraints, to finish getting down to the root cause.
SPC is deeply rooted in the quality movement. One hallmark of "quality" is the reduction of variation. As variation decreases, the UCL and LCL approach each other. In the case of the people in the preceding cartoon, the reduction of variation would come not from hiring new people, but from creating a system that allows them more consistent (and hopefully higher) production. This would be equally true if the preceding control chart were ball bearing diameters instead of human performance.
In the vernacular of SPC, anything outside the UCL/LCL limits warrants investigation and is called an "assignable cause", or sometimes a "special cause". Anything within those limits is termed a "chance cause", a variation born of random noise needing no investigation. If one wants to reduce the variation or raise the numbers en-masse, the system common to all the numbers must be investigated.
There are many books on the subject. The book I own is called "Understanding Statistical Process Control by Donald J. Wheeler and David S. Chambers. This book contains all the equations you need to calculate the UCL and LCL, as well as the math to diagnose numerous problems that can be evaluated statistically. As is obvious from this article, I haven't even scratched the surface of the information contained in this book.
It's the only technology Troubleshooting process I know of that addresses the mental outlook of the Troubleshooter, instead of considering him or her a perfectly rational robot.
To really understand the beauty of Jack's methodology, you need to visit his Troubleshooting web page (in the URL's section of this magazine). Throughout the explanation of his method runs a message of "be careful, trust nothing". Obviously, an in-process (and therefore incomplete) design is buggy, and may not behave as expected. There could be double and triple root causes, and the system may not be designed as you think it is.
If you're in the middle of creating an electronic design, use Jack's methodology. Although I personally use the UTP in troubleshooting software under design, it's very possible that Jack's would be better optimized for that. Basically, when designing anything, make sure you're familiar with Jack's 6 step loop.
| Era | Name | Range | Description |
| 1 | Observational Troubleshooting | From invention of the bow and arrow until the invention of the steam engine (8000 BC to 1700's) | Observation only. Systems under repair have all components visible, so the problem is obvious. Little diagnosis needed. On the other hand, repair/replacement of component requires precision, one of a kind work. |
| 2 | Intuitive Troubleshooting | From invention of the steam engine until the 1970's | Observation and non-rigorous diagnostic process. Systems under repair still contain only a few components, though some aren't visible to the naked eye. Diagnosis required, but doesn't need to be rigorous. Replacement parts likely to be available from a vendor, but may be difficult to replace. |
| 3 | Process Troubleshooting | From 1970's until the present | Observation and rigorous diagnostic process. Systems under repair contain many (>10,000) components, most abstract or invisible to the naked eye. Non-rigorous diagnosis produces circular search and rework. Rigorous diagnosis required. Replacement parts available from a vendor, and due to modularity often easy to install. Software components are often replaced in five minutes with a few keystrokes. |
| 4 | Technologically Enhanced Troubleshooting | From now until the next era | Observation and rigorous diagnostic process, aided by context-relevant technology-served information (Troubleshooting process aware smart manuals). Systems under repair are now hugely complex, not always completely modular. Observation and rigorous diagnostic process alone takes too long, because no human can have the complete Mental Model, manual and diagnostic information in his or her head. Replacement parts are stock. |
I met Jim when he emailed me in 1996, wanting some advice on placing a Troubleshooting Process in an automated diagnostic system. At the time he was a highly placed training executive in GM. If it had been anyone else I would have chalked it up to "another expert system marketed to replace a human Troubleshooter". But Jim knew his stuff, and it was obvious he understood Troubleshooting Process through and through. So we talked frequently throughout 1996 and the first half of 1997.
But I really didn't understand the finished product. I'd heard so much about it, but didn't understand what the finished product would be like. Until 1999, when I tried it in at a conference. It was incredibly easy to use. Jim Roach gave several demos where people used it to find bugs (intentional malfunctions) placed in a Cadillac.
This Troubleshooting Process is highly optimized for situations in which the vendor has provided voluminous service documentation, including quickchecks, error code documentation, predefined diagnostics and the like. The process starts out with symptom acquisition and reproduction. Next what would be called General Maintenance in the UTP, including tech bulletins, diagnostic codes, and the like. This is followed possibly by a divide and conquer session, guided to the extent possible by existing predefined diagnostics. The final step is repair and testing.
So far it sounds like the Universal Troubleshooting Process. But if you look at the details, the Intelliworxx model assumes that most problems will be solved with the help of existing documentation, and that the Troubleshooter won't need to devise his own diagnostic tests. Given the volume of system information in the smart manual, for the first time this becomes a viable assumption. Indeed, combined with a smart manual on a voice actuated, ruggedized hands-free computer, the Troubleshooter has instant, just in time access to exactly the necessary information. At every stage of the game, the first priority is to look at existing documentation. That documentation is a smart manual (or as Intelliworxx would call it, a mentoring application). Only when all documentation has been delivered to the Troubleshooter, without a solution being found, does the Troubleshooter go "offroad", creating and testing his own hypotheses. At that point, the well equipped Troubleshooter would know the Universal Troubleshooting Process, which is optimized for those times when relevant system documentation is not available.
Authoring such a smart manual is costly, but so is a truly detailed paper manual. This Troubleshooting Process enhanced, voice actuated, hands free smart manual, is the first tool integrating effective, low cost information lookup with Troubleshooting Process. For the first time it's quicker to follow predefined diagnostics than to create your own. In industries providing detailed, accurate and timely system information (the automotive industry is a perfect example), it can multiply productivity.
Contrast this with an industry like proprietary computer equipment and software, where documentation is incomplete and scattered. In software diagnosis, if you haven't found the info in 10 minutes you're probably better off diagnosing it yourself. We software guys can only dream how fast Troubleshooting could be if we had instant, as needed access to all accumulated knowledge of the machine or system.
A link to the Intelliworxx website appears in the URL's section of this magazine.
| Well Defined Systems |
| Fuzzily Defined Systems |
| Method | Repro- ducibility |
System definition/ document- ation |
Safety | Availability | Comment |
| Universal Troubleshooting Process |
Reproducible to semi frequent intermittents |
Well defined to almost well defined | Non-critical to individual injury risk | Free to read, very extensive description on
the web.
Modest licensing fee for in-house training. www.troubleshooters.com/ tuni.htm |
Optimized for machine and computer system troubleshooting, especially when vendor support is lacking. |
| Intelliworxx Era 4 tools (Jim Roach et al) |
Reproducible to semi frequent intermittents |
Extremely well defined only | Non-critical to individual injury risk | Available for purchase from Intellex. Was free to read on web, and might be again. Requires system specific software and electronic documentation with scripts. | The fastest way to troubleshoot machines and systems for which process-based troubleshooting scripts are available. |
| 6 Step Loop Jack Ganssle |
Reproducible to semi frequent intermittents |
Well defined to almost well defined | Non-critical to individual injury risk | Free to read on web. www.ganssle.com/ articles/atblsho.htm |
Optimized for troubleshooting used as a part of the design process. |
| Statistical Process Control |
Reproducible to semi requent intermittents |
Well defined to barely defined | ? | Readily available in book/textbook form. Training and college courses available. | Optimized to fix problems with processes running over a long interval of time. |
| Theory of Constraints |
Reproducible to frequent intermittents | Well defined to deducible / documentable | Non-critical. Augment with other methodologies in safety critical situations | Available in inexpensive and easy to read books. Heavy consulting/training available from Goldratt institute. | Optimized to solve problems whose symptom descriptions include "too little", "too much", "too long", etc. Works extremely well in fuzzily defined systems, used extensively in manufacturing |
| Generic Problem Solving |
Reproducible to somewhat sparse intermittents | Deducible / documentable to barely defined | Non-critical to seriously critical | Almost impossible to find on web. Typically marketed to large corporations as expensive training. | Optimized for fuzzily defined problems in which little can be assumed. |
| Re- engineering |
N/A | Well defined to undefined | Best relegated to non-critical | Very well explained in Hammer's "Reengineering the Corporation". Many different flavors. | Optimized for businesses so far off the mark that Theory of Constraints and "Constant Improvement" are not an option. |
| Root Cause Analysis |
Sparse intermittents to single events |
Well defined to deducible / documentable | Used in nuclear powerplants. Addresses all safety issues | Very well explained in Ammerman's "Root Cause Analysis" book. Other books available. Training available. | Optimized for sparse intermittents and single events -- detective work. Especially necessary in safety critical environments. |
There was a time I answered that question affirmatively. Not that I ever successfully used it to solve an interpersonal relationship, but problems are problems, right?". I actually made the mistake of using relationship problems as examples in some courses. Sometimes it worked, and sometimes it bombed very badly.
Eventually I backed off my claim of being able to solve relationships, guaranteeing only to solve problems in "well defined systems". But I still didn't know why the Universal Troubleshooting Process didn't work on fuzzily defined systems.
To figure that out, I had to learn about the anatomy of a problem. You see, a well defined system problem is a subset of generic problems. A well defined system comes with two additional pieces of information for the Troubleshooter:
But the as-designed state and behavior is a vital distinction. Here's why...
The most basic definition of problem solving is the following 2 step process:
They both work 75 hours a day, and have responsibilities for their son and his activities. This obviously leaves no time. Should they:
Generic problem solving methodologies are equipped to address both the problem state and the solved state. The Universal Troubleshooting Process is not a generic problem solving methodology, and therefore is sufficient only in the subset of problems in which the solved state is "restore to the as-designed state and behavior". So why would anyone use the Universal Troubleshooting Process, when generic processes handle all problems?
Simply stated, tools meant to design and to weigh alternatives are wasteful in problems where the solved state degenerates to "the as-designed state and behavior". This issue has an article called Cars and Tanks that discusses just how wasteful this can be.
So the purpose of this article so far has been to show that generic problem solving methodologies and problem solving methodologies optimized for well defined systems are neither interchangeable, nor viable substitutes for each other.
The previously listed two step representation of generic problem solving actually leaves out a couple things. A more realistic generic problem solving process would look like this:
.-------------------------------. |
There are different kinds of future problems to prevent. One is a recurrence of this same problem. That's achieved primarily by the problem state analysis. Then there's the creation of different problems. This is an area for study in the solved state analysis.
Many of us think most creatively when exercising. I've designed many a computer program while skateboarding, bike riding, or walking through the woods.
The Universal Troubleshooting Process's Troubleshooter's mantra, "How can I narrow this down just one more time?" can easily be adapted to creativity jump starting. There are other questions that can jump start creativity:
If you're lucky enough to be in a company whose budget allows you receive generic problem solving training from a vendor, do it. If not, I'd suggest a thorough reading the web material of Dr. Charles Camp and Fred Fred Nickols. Both are excellent, and the URLs are in the URL's section of this magazine.
And a word of warning. One day a generic problem solving vendor may try to sell you generic problem solving training for your technologists, even though the technologists primary troubleshooting is technical (restoring well defined systems back to their as designed state). These vendors may even offer to train you to be a trainer in their methodology, with the obvious resume benefits.
Sounds great, but be very careful. Because when it comes to fixing well defined systems, if your organization uses a generic problem solving methodology and your competitor uses something like the Universal Troubleshooting Process, they'll clean your clock.
Read the next article.
Imagine driving to work in a M1A1 Main Battle Tank, also called an Abrams tank. It has tracks instead of wheels, and it can go absolutely anywhere. It can roll over obstacles 42 inches high. It can cross trenches 9 feet wide. It can go up a 60 degree slope. And due to its almost impenetrable armor, its 120mm main gun, and three auxiliary machine guns, it can traverse the most hostile environments. An M1A1 main battle tank can go almost anywhere on land, including the freeway. So why use a car to go to work, when cars accommodate only a small subset of terrains?
One reason is that the M1A1 gets less than 1 mile per gallon of gas. Working only 10 miles from home, you'd pay $150/week in fuel alone. On those rare occasions when the freeway travels full speed, the M1A1's 45 mph maximum speed is a liability. At a length of 32 feet, one inch, a height of 9.5 feet, and a width of 9.5 feet, parking is a problem.
There's no doubt the M1A1 can get you to work. But your friends driving Chevy Luminas get there faster, cheaper and more conveniently. Yes, the M1A1 can go anywhere, but that ability is costly indeed.
Reminds me of companies selling general problem solving training to those requiring electronic, mechanical or computer Troubleshooting.
Mechanical, electronic and computer troubleshooting is a subset of problem solving. Machines and automated systems are well defined systems. By that I mean they have a documented and well defined state and behavior. Fixing them requires only returning them to their as-designed state and behavior. You needn't analyze the solved state, with its heavy design and creative thinking requirements. You needn't ask how you want the machine to perform after repair -- you already know that. It must perform as designed. You needn't ask if there's some better way you can do it. All that's necessary is to get it back to its as-designed state and behavior.
Some training vendors are all too happy to sell you a generic problem solving course for your technical people to use on machine/computer/software problems. Such generic problem solving methodologies contain several time consuming steps necessary only to design the solved state (which degenerates into the as designed state and behavior for machine, computer and software problems). The vendor might justify this by mentioning that the generic problem solving methodology can solve all problems, including those of machines, computers and software. They're telling the truth, and it's about as practical as trading in your car for an Abrams tank.
If you want to win, you go to war in a tank and the office in a car. If you want to win, you fix technical problems with a Troubleshooting Process optimized for technical problems, and fuzzily defined problems with a generic problem solving methodology. If a person solves both types of problems, train him in both methodologies.
So the question you need to ask is this: How would it affect my business if my competitors used more optimized Troubleshooting methodologies than my company?
Except for the Universal Troubleshooting Process. The UTP's Step 1 (Get the Attitude) and Step 9 (Take Pride) are inward focused.
Outside of Star Trek and Isaac Asimov novels, I've never met a Troubleshooting robot. What I have met are technicians angered to the point of throwing equipment across the room, and computer managers panicked to the point of paralysis. Frequent failure results from methodologies that doesn't at least consider the person doing the fixing. None of us is a robot, and if we haven't learned to control our emotions, those emotions can wash away all logic.
But the Universal Troubleshooting Process isn't human-centric. Only two of the ten steps are. The majority is procedural. In machine/technology repair, all you need to achieve is the as-designed state and behavior. Contrastingly, many methodologies are almost entirely focused on the person doing the problem solving. I call them human-centric methodologies.
And that's exactly what's needed when the system under repair is the problem solver himself. In such cases, the problem solver is troubleshooting himself, surrounded by an environment for which he has limited control. Personal problems are typically triggered (I didn't say caused, I said triggered) by either changes in the environment around the person, or a "bad break".
Personal problem solving is complicated by several distinctions:Note: Such "self help" can be propagated by trainers training others in these methodologies. They can even be extrapolated to solution by consultants using human-centric principles to fix business problems, but this runs the risk of the "program of the month" label if not done in a way that respects employees' intelligence, time and motivation.
When it comes to insulting the intentions of the reader (or in this case listener), certainly radio's pop-psychologists corner the market. The listener calls in with a serious and complex problem, and the first thing the radio guy does is paints the listener as weak, stupid and unethical. Yeah, that's real productive!
A problem solving methodology is effective only if followed. It is followed by a reader only if the investment is justified by the expected return. The average reader has been unsuccessful with some human-centric methodologies in the past, and is thus skeptical, meaning the expected return is uncertain. Therefore, the book expounding an overly complex or demanding methodology is read but not followed. The methodology offering a quick and easy route to small benefits, followed by a staircase of additional investments with additional gains, is followed.
There are effective methods of "putting across" complex and difficult methodologies. One method is charging a lot of money, so it makes it worth the student's while to devote a month to learning and practicing the methodology. This is accompanied by live lectures, one on one consultation, tapes and exercises. This will work with methods that, once fully learned, are truly beneficial. But it requires extraordinary faith in the program. And unfortunately, some are in it just for the money. As the old saying goes, once bitten twice shy.
Another component of benefiting even the skeptical reader is use of plain language. Methodologies defining their own terms, and especially those engaging in psychobabble, are much less credible to the intelligent person.
Purveyors of human-centric methodologies would be wise to study the merits of the Universal Troubleshooting Process, which itself is not human-centric. The UTP requires very little buy-in -- merely hanging the list of steps on your wall produces improvement. A single day of studying step 6 produces another vast improvement. And as the reader gains confidence, there's a continuing stepwise route to study and improvement. And the reader can pretty much determine the order and pace of the steps.
The documentation of the Universal Troubleshooting Process is devoid of jargon. Extra effort has been taken to use plain language to define and discuss its concepts.
Human-centric problem solving methodologies are optimized to solve personal problems, but they can be helpful solving other problems. Consider that many highly paid technical Troubleshooters are limited by their emotions, especially in the face of extremely difficult problems. All other things being equal, including training in technical Troubleshooting Process, the technical Troubleshooter who has mastered an effective human-centric problem solving methodology will be more effective solving technical problems.
There are many outstanding human-centric methodologies out there. Following are discussions of these human-centric methodologies:
#3 deals with use of time and prioritization. If you're a regular
reader
of Troubleshooting Professional, you know I believe in easiest-first
prioritization.
But that's WITHIN the prioritization methodology Covey discusses in #3:
| Urgent | Not Urgent | |
| Important | This is firefighting, and should be avoided |
Spend your time here, so important stuff gets done before it's urgent |
| Not important | Waste of time | Waste of time |
Blow off unimportant tasks. If a task doesn't help you reach your goal, and not doing it won't prevent you from reaching your goal, don't do it. Now of course, somebody else might consider it urgent that you do unimportant tasks. Try to work it out so you're not required to do them, because they're a waste of time. Or figure out a way to make them important in reaching your goal.
Note the similarity here to my admonition not to troubleshoot unprofitable work. This is discussed in the August 2000 issue of Troubleshooting Professional.
One might instinctively think important and urgent tasks are where we should spend our time. But in fact, that's not true. Tasks always take longer when they're urgent. Urgent tasks spawn the need for explanations, written reports and meetings. Many individuals you work with react to urgency with anger or panic, both of which lead to costly mistakes. And of course, if you go over the deadline and don't sell the product or get something to market, that's extremely costly.
So the object is to have all the important stuff done before it gets urgent, which is why once you've gotten your fires put out, spend all possible time on important tasks that are not yet urgent, and make every effort to prevent important tasks from becoming urgent.
Covey explains that the first three habits are done in isolation -- you don't need to collaborate to accomplish them. The next three are collaborative.
Thinking Win/Win usually promotes success, depending on the definition of success. We all have seen enough of the world to know it's not an absolute prerequisite for success. We all know of companies succeeding through playing dirty tricks on their competitors rather than making good product. But in the vast majority of cases, the win/lose crowd finally become losers themselves, either because the ethical emptiness of their lives leads to substance abuse or other problems, or because they run afoul of the law. Or both. The intelligent person knows that sometimes each of us must "go to war", but generally speaking, Win/Win is the best policy.
Most sales books I've read have a paraphrase of habit 5, "Seek First to Understand... Then to be Understood". Sales books typically mention you have 2 ears and one mouth, and to use them in proportion. In a technical Troubleshooting scenario, you'd never attempt a fix before knowing the root cause -- you need to understand first. But understanding is not always so easy. Psychology 101 teaches us there's a principle that most people attribute their own actions to their situation, but they attribute the the actions of others to the others' personalities. I drive 80 mph on the freeway because I'm late to my wedding. The guy in the red car drives 80mph because he's reckless. One cannot really deal with others until one understands their situation. You need to walk a mile in the other guys shoes.
Covey's habit #6 is "Synergize". Work with a group in such a way that the whole becomes greater than the sum of the parts. I've found that if you put 10 people in a room they can accomplish just about anything, because there's almost no piece of knowledge not possessed by at least one. If the people practice the first 5 habits, #6 can be correctly accomplished. Once one can work synergistically with a group, he or she can accomplish amazing things. So what's left? Why is there a habit #7? For exactly the same reason there's a step 9 (Take Pride) in the Universal Troubleshooting Process.
Consider this: If you saw wood for a living, you'd surely sharpen your saw when it got dull. Otherwise, your productivity would plunge. Sharpening the saw is Covey's 7th habit.
People get dull after protracted periods of hard and effective work. They must be sharpened. Covey lists four categories of such sharpening -- physical (exercise, nutrition, sleep), mental, spiritual, and social/emotional. I'd like to add a fifth -- savoring triumph, which definitely encompasses mental and social/emotional. If done during a walk, skating, bike ride etc., it encompasses the physical. And you know what? I've had cases where savoring triumph approached a spiritual activity.
Covey's 7 habits are my favorite human-centric problem solving methodology. It's common sense, without inordinate amounts of early 90's mission statement pabulum. And it's so simple that an average individual can read the book and begin to put it into practice. One thing I really like about the 7 habits is they avoid the "believe in it, and it will come" trap, instead portraying faith as one necessity among many.
Schuller wrote this book to help the fearful and hopeless in that dreadful year. Above all, this book is exquisitely inspirational. Read just the first chapter to see how Schuller weaves the present (in 1982) economic disaster with his own hard and poor childhood, working back forward to the present, ending with what all but the most hardcore Atheist would call a gift from God. Even the Atheist would call it a 9.2 on the Richter scale of lucky breaks. Armed with the "anything is possible" feeling the first chapter bestows, Schuller lays down several sound principles, tips and techniques for snatching victory from the jaws of defeat.
Schuller gives some great marketing advice. His "how do you catch a marlin" discussion details the need for access to a market for your product. His "possibility thinking" discussion with its 10 alternative method is the self-help equivalent of "how can I narrow it down just one more time?" question in technology Troubleshooting.
In every chapter, Schuller has lists to be followed, and examples of people succeeding by following those lists.
This book is a must-read for anyone facing seemingly insoluble problems. After all, it was written for just such an audience.
The basic idea is that you're effective when you're in a good and creative mental state. Rather than waiting for external events to put you in that state, you can put yourself in that state and then reap the benefits. As Abraham Lincoln said, "a man is just about as happy as he decides to be". Of course, I understand Lincoln had a problem with depression :-)
I believe that the NLP techniques I've read in Anthony Robbins' books "Awaken the Giant Within" and "Unlimited Power" are excellent personal problem solving techniques that cannot be learned by skeptics, or even the unconvinced. They require a huge commitment, maybe a month or more, to practice and master the techniques. I see no "low hanging fruit" that can boost results in a day or two. Robbins includes many real-life exercises you need to do. If you don't do them, you'll get little from the books.
If you believe your problems can be helped by a better life outlook
or a better use of your mental resources, and you're willing to invest
a lot of time, I'd highly recommend getting these books, and taking the
significant time it takes to work through and master their exercises. I
cannot recommend these books, or the methods they espouse, to those
unwilling
to make a substantial commitment to mastering their techniques.
Note: There's a Tony Robbins book called "Notes from a Friend: A Quick and Simple Guide to Taking Control of Your Life". It's based on "Awaken the Giant Within" and "Unlimited Power". It may be a way to ease yourself into these techniques without big time prior commitment.
To solve this type of problem, Keith Ellis recommends, in his article titled "Affirmations", saying something like this:
I choose |
joyfully |
become a great Troubleshooter |
| Mr. Ellis recommends we always recognize that every change we make in our life is a choice. | Mr. Ellis recommends we maximize the power of every affirmation by injecting positive emotion, such as the adverb "joyfully". | This is the actual goal of the affirmation. |
Once again, this solves only problems whose root cause is attitude. But it's powerful, because a single destructive attitude leads to tunnel vision. If your goal requires $100,000 to start, and you've got only $859 in the bank, it's just possible that an affirmation like this could break the conflict:
I choose to joyfully find inexpensive ways to quickly reach my stated goal.
The attention and interest steps are done during prospecting, with desire split between prospecting and sales calls. Conviction and action are done during an actual face to face meeting (usually). This meshes very nicely with the sales funnel, described later in this article.

After reading many books, and observing the successes and failures of myself and others, I've reached the conclusion that sales and marketing boil down to having Access to a Market for your Product. It's the matchup of Access, Market and Product that IMHO is a prerequisite for good sales. You don't sell your acting skills in Wisconsin or your farming skills in Los Angeles. Because access is hardest to obtain, choice of new products should always favor the markets to whom you already have access. You can slowly grow the boundaries of your market access area, but don't make a product outside it.
Some people think they don't have access to any market. Not true. All one needs to do is look around at his friends. That's access. What kinds of people does one get along with well. Some of us get along with the upper crust, and some of us have friends in low places. We sell to the people we get along with.
Almost everyone gets requests for advice and help. Many of these requests are for favors that don't involve money, but make no mistake, if people are asking you for advice and help, you have something to offer. The trick is to expand your access outside your immediate group, because it's often hard to charge a fee to friends. Sometimes you can even sell your knowledge in the form of books.
Before you go out and base your entire sales strategy on my ideas, keep in mind that I'm just a middle class guy, and with my products, if I were a great salesman I'd be a multi-millionaire. But I think once I get the execution down correctly...
He also concentrated on getting more business from other departments in businesses he sold to. For instance, he was in the Sears Tower so much that he was able to expand from labels to tags, selling them to many different departments.
Nope, he just made sure his quality was as good as the Japanese, and then buried the extra cost in the cost of the entire item. A $40.00 dress has a single label. A Japanese one might cost a penny, the American one two cents. That penny difference is 0.025% of the sales price. It's negligible, and Dad approached it that way. It was much easier to buy from him, and the cost was 0.025% of the dress. It's a no brainer.
It could be said that burying the cost in the big picture is practical only with very cheap items. But in fact it's simply easier to explain and understand with cheap items. If you program computers and charge $20.00 more per hour than the competition, but you can better demonstrate that you're likely to do it right, you're easy to buy from. Now multiply the $20.00 differential by 2500 hours for a one year project making a cost differential of $50,000. Now total the hardware and software costs of the project, training, administration, as well as the coding cost that is not differential. In many cases, your differential comes out to be peanuts. And for the icing on the cake, find some way you can save them more than that small percentage, making you cheaper.
When Ralph complemented, he complemented the person. When he criticized, he criticized their action. I think he basically believed people are good.
Unfortunately, there's no way you can package Ralph's basic belief in the good of humanity. Few of us have that outlook. But to the extent possible, try to see your customers and prospects as cool people you might like to get friendly with some day. You'll be glad you did.
Not too shabby for a site with no IPO and no venture capitalists. But I had great marketing advice from Kassof.Com. Basically, Mark emphasizes seeking an audience you can realistically attract, and super-serving them. Being a technology and Open Source kind of guy, I super-served the technologist and Linux audience.
Kassof emphasizes that with so much noise in the media, you need to be a little outrageous to be heard. So I did. I told my true feelings about Microsoft. Many friends told me I was doing the wrong thing. They told me I'd be closing doors on myself. They told me I'd blow off 95% of my potential audience. And they were right.
But that remaining 5% loved Troubleshooters.Com, just as Mark predicts in his insights. One of his quotes is that "These days, the 'middle of the road' is a good place to get run over".
I've just scratched the surface here, but it would take 10,000 words to fully explain Kassof's marketing strategies, and I don't have the bandwidth. So go to Kassof.Com, and study both his "Research Insights" and his "Quotations of Chairman Mark". Links to both, as well as to his main page, are in the URL's section of this magazine.
You might also wonder what marketing has to do with sales. In a big company maybe very little. But in a small company, prospecting begins with marketing and transitions to sales as the prospects become more interested.
Don't let it throw you that Mr. Kassof's tips are targeted at the radio industry. They work on the web too. Believe me :-) And for any of you out there who are involved with radio, use him. My reading of his website tells me that if I needed radio research, I'd go to him, because he's independent and not affiliated with a radio chain or consultant, he's unbiased, and he knows radio.
This book makes the point that too many salespeople and organizations hammer the best few until they've sucked it dry, and then discover their abandonment of the upper levels means they need to wait months to refill that level. So they hammer the upper levels and finally get an influx of best few. This explains certain extreme cyclical sales events.
In many other ways, this book takes a systemic and scientific view of sales. I recommend it.
First, be aware that my copy of "How to Master the Art of Selling" is the second edition, which appears to have been copyrighted in 1982. It's probable that Mr. Hopkins has changed the book a lot since then.
My second edition book gives many, many examples. That's a good thing. My wife's a Realtor(R), and I just mentioned an example from this book that directly applied to a situation she was in. Especially refreshing is that Mr. Hopkins hasn't gone overboard on "consultative selling". Tom isn't afraid to admit that he likes to close, and likes to close hard. And he's not afraid to imply that not all prospective customers are peers of Einstein.
Which brings up the problem. Many of the techniques he espouses in my Second Edition book are insulting to an intelligent person. Anybody trying Hopkins' "Ben Franklin Balance Sheet Close" or the "Porcupine Test Close" on me would find themselves out the door (without an order) in a hurry.
"How to Master the Art of Selling" is a must-read for anyone in sales. The author has obviously been there and documented his strategies and tactics. Just carefully temper your adoption of those suggestions that seem to insult the buyer's intelligence. And if you're contemplating a sales career, or new to sales, be sure to pick up a copy of Selling for Dummies".
There's a myth that consultative selling started in the 1980's. Check out this line from the 1949 edition:
"I resolved right then to dedicate the rest of my selling career to this principle: Finding out what people want, and helping them get it."
Don't worry though, Bettger's not just a consulatively correct wet noodle -- he also suggests the "sign by the X assumptive close".
Unbelievably, this book is still in print, copyright 1992. It is 24 hours available at Amazon, where it's ranked #7,966 and has a five star review average. Frank Bettger looks about 35 years old on the 1949 copy cover, which would have made him 78 in 1992. To me, this book's staying power makes it not only a classic, but a tried and true resource.
This book is obviously not a complete sales problem solving methodology, but serves beautifully in the function of example. I believe the seasoned salesperson would profit from this book, right along with the newbie.
In a world where even we salespeople start to believe in the plaid sportcoat car salesman and Arthur Miller's Willy Loman, Shook's deep love and admiration for his profession makes the reader stand a bit taller. If you EVER contemplate selling anything, get this book.
So from my understanding of Hammer and Champy's definition of reengineering, its optimized for those cases where the business is so out of touch with present day realities as to be "totalled", like a car hitting a bridge at 120mph or a house burned to the ground. If you'd like to "improve" your business while keeping its core advantages, my understanding is that reengineering is not the way to go.
Obviously, my understanding of the term is crude at best, so please don't take my word for it. Read the book for yourself, and see if I've been overly critical. I invite all more knowledgeable on reengineering to write letters to the editor (instructions near the bottom of this page) so that next month the truth about reengineering will surface.
I believe that one of these tools, Covey's "The 7 Habits of Highly
Effective
People", rises above the others to take its place among general problem
solving methodologies. It's true you can't fix a car using his
methodology,
but you can sure use it to make yourself a better mechanic.
| Category |
TITLE |
AUTHOR |
Comments |
| Troubleshooting
well defined systems |
Troubleshooting
Techniques of the Successful Technologist |
Steve
Litt |
Troubleshooting
methodology optimized for well defined systems, and numerous easy,
cheap, and safe test points. Includes Bottleneck Analysis for problems
of degree in well defined systems. |
| Tangible
general problem solving |
The
Root Cause Analysis Handbook |
Max
Ammerman |
Optimized
for sparse intermittents, events, and extreme safety criticality. Can
drill down root cause past components all the way to human factors. |
| The
Goal |
Eliyahu
M. Goldratt |
Optimized
for problems of degree in both well defined and fuzzily defined systems. |
|
| The
New Rational Manager |
Charles
H. Kepner and Benjamin B. Tregoe |
Optimized
for expensive, unsafe or difficult testpoints, as well as fuzzily
defined problems. |
|
| Tangible/Personal
problem solving |
The
7 Habits of Highly Effective People |
Stephen
R. Covey |
Optimized
for personal performance of the Troubleshooter/Problem solver himself.
A classic, very credible and helpful. |
| Personal problem solving | Tough Times Never Last, But Tough People Do | Robert H. Schuller | Optimized
for personal performance. A very credible treatment of positive mental
attitude, written for the sufferers of the 10% unemployment in the 1982
recession, but applicable to anyone facing personal challenges or
wanting to rise beyond his/her comfort zone. |
| Awaken the Giant Within | Anthony
Robbins |
Optimized
for personal performance. Very detailed and demanding, not for the
faint of heart. |
|
| Sales
problem solving |
Strategic Selling | Miller and Heiman | In
my opinion, extremely credible, process oriented, emphasizes the "sales
funnel". Top notch. |
| Selling for Dummies | Tom Hopkins | In
my opinion, this beginner's guide to sales is factual, and walks the
middle path between wimpy "nonmanipulative" sales and aggressive sales
tricks. |
|
| How to Master the Art of Selling | Tom Hopkins | In
my opinion, contains many great ideas, but also contains many
aggressive sales tricks that would infuriate an intelligent buyer. |
|
| How I Raised Myself from Failure to Success in Selling | Frank Bettger | In
my opinion, this half-century old classic is good, common sense, with
tips on sales techniques and also an emphasis that you must satisfy the
customer. |
|
| The Greatest Sales Stories Ever Told : From the World's Best Salespeople | Robert L. Shook | In
my opinion, this book's stories teach by example. Each story
illustrates a sales technique or quality. A must-read. |
According to Fred Nickols' website, he's a writer, consultant, and executive. A further perusal of his site reveals his credentials to be, putting it mildly, outstanding. Be sure to read Fred's articles and his distance consulting page. His articles on problem solving are insightful, and all too rare on the web. His URL is in the URL's section of this magazine.
Charles V. Camp is a Professor of Civil Engineering at the University of Memphis. His web notes for the CIVL 1101 course he teaches, Civil Engineering Measurements, contain some of the best problem solving content on the Internet. I'd suggest you read all the content related to problem solving. The URL is in the URL's section of this magazine.
For time reasons, I didn't detail Fred's and Charles' contributions to problem solving, but their content is outstanding and a must-see for any problem solver.
Imagine how much easier diagnosis of intermittents would have been with a continuously running strip chart recorder. I could have looked for the onset of the symptom, and seen what else happened around that time. I could have observed which voltages changed.
Enter the Linux logs, which act pretty much like strip chart
recorders.
By looking back on the logs, you can see not only the onset of the
problem,
but the entire encompassed syndrome. Here are some of the major logs
used
in Linux:
| /var/log/messages | The granddaddy of all logs, this is the major repository of system messages. |
| /var/log/boot.log | This log records messages issued during the boot process, and is handy for deducing the as-booted state of the computer, as well as getting hints as to what went wrong during bootup. |
| /var/log/dmesg | Messages from the kernel ring buffer -- low level boot info |
| /var/log/secure | Basic security messages including telnet logons. |
| /var/log/cron | Log of running of cron jobs. |
| /var/log/maillog | Mail log |
| /var/log/netconf.log | A record of network events such as route changes and dhcpd |
| /var/log/security.log | This log shows security concerns such as world-writable files, open and listening ports, changes in security, and the like. Pay special attention to the "diff check". This file is written by a daily cron job. |
| /var/log/security/ | This directory contains intermediate files contributing to the maintenance of the security.log file. |
| /var/log/xdm-error.log | Use this when troubleshooting your Xwindows video. |
| /var/log/httpd/ | This directory contains logs pertaining to the web server. |
| /var/log/samba/ | This directory contains the various logs for the Samba file and print server. |
These logs can be used for more than just after the fact detective work. Using the tail -f command, you can view messages in real time as you exercise the system. Better yet, most daemons have methods to increase or decrease the verbosity of what they write to logs, enabling you to "drill down" to execution details. When combined with access to the source code, this becomes a powerful Troubleshooting tool. To find how to change the log verbosity of a daemon, look at the man page of the daemon.
When troubleshooting Linux, always look at the relevant log files.
Enter source available software. Now you can peer into the actual design of the software. This can be done at several levels.
The simplest way to use the source is to crank up log levels, search for the source statement issuing a suspicious log message, and work backwards through the source until you come upon an interesting question. This can be done with minimal knowledge of the software.
As you gain a little more expertise, you can use the source to form a Mental Model of the software, and make deductions and form new tests based on that Mental Model.
Finally, you can actually change and recompile the source to test hypotheses. Although this is extremely powerful, care must be taken not to cause harm. Original source files must be backed up, the original executable files must be backed up, and it's best to do this on a non-live system, if one exists and if the symptom can be reproduced on it.
Source code needn't be thoroughly digested to be helpful in Troubleshooting. Often you can start in the type source distribution directory, and search for a term or phrase like this:
$ grep -i -r "searchterm" *Such searches often yield just the right information within a few minutes.
General Maintenance is especially powerful against non-component flaws -- dirty contacts, loose bolts and other things not appearing on the schematic diagram. It is also extremely powerful against intermittents. But neither of these situations pops up frequently in Linux. As a rule, software has few "non components". Especially software whose source code is available. And as far as intermittents, Linux is a stable and robust operating system that seldom exhibits intermittents.
General Maintenance has one huge downfall. It prevents positive ID of the root cause. If the symptom goes away after you clean all switches and controls, you don't know which switch, you don't know which contact within the switch, and you don't know why the contact got dirty or oxidized. This is obviously taboo in a safety sensitive situation, but even in a business computing environment, it's not desirable.
In fact, the system logs are often a more productive tool in diagnosing intermittents. And it's all too easy to conduct tests with the various software tools that come with Linux, in order to positively determine the root cause, and toggle it.
So except in cases of complete befuddlement, don't reboot a Linux box as a Troubleshooting step. It might not even be desirable to restart a service, although this is done often. Try to find the root cause without General Maintenance.
This isn't necessarily true of Linux. It's often better to upgrade, thereby keeping dns, dhcp, samba, apache and other configurations intact. Installing fresh means restoring each of those configurations (and many, many more) from documentation or (human) memory.
The downside is that on a Linux system that's gone through a long series of upgrades, the system state is not fully known. I recently heard of somebody who had continuously upgraded a mid-90's copy of yggdrasil and still has it running today. Almost all the yggdrasil code is gone, but over the continuum of time, it's the same system. Obviously, such a system could not be replicated from distribution.
When should you finally bite the bullet and install Linux fresh? I guess when the system becomes so unknown that you cannot troubleshoot it.
Remember to restart the appropriate daemons or services after changing a config file. My experience is that daemons recognize certain config file changes immediately, but need to restart in order to recognize them all. After changing a config file, you're in an undefined state until restarting the daemon or service.
If you do any Troubleshooting tests that compromise security, try to get the box off the network before doing them. Write them down so you can quickly undo them.
The bad news is that an owned Linux box is more dangerous than an owned Windows box. The good news is that a Linux box can be made much more secure than any Windows box.
A discussion of security is very much beyond the scope of this article, but there are many fine books and websites devoted to the subject. Unless you're running a single machine that does not log into the Internet or LAN, you need to understand security.
By submitting content, you give Troubleshooters.Com the non-exclusive, perpetual right to publish it on Troubleshooters.Com or any A3B3 website. Other than that, you retain the copyright and sole right to sell or give it away elsewhere. Troubleshooters.Com will acknowledge you as the author and, if you request, will display your copyright notice and/or a "reprinted by permission of author" notice. Obviously, you must be the copyright holder and must be legally able to grant us this perpetual right. We do not currently pay for articles.
Troubleshooters.Com reserves the right to edit any submission for clarity or brevity. Any published article will include a two sentence description of the author, a hypertext link to his or her email, and a phone number if desired. Upon request, we will include a hypertext link, at the end of the magazine issue, to the author's website, providing that website meets the Troubleshooters.Com criteria for links and that the author's website first links to Troubleshooters.Com. Authors: please understand we can't place hyperlinks inside articles. If we did, only the first article would be read, and we can't place every article first.
Submissions should be emailed to Steve Litt's email address, with subject line Article Submission. The first paragraph of your message should read as follows (unless other arrangements are previously made in writing):